






6
Sep
基于双向LSTM和迁移学习的seq2seq核心实体识别
By 苏剑林 | 2016-09-06 | 141975位读者 |暑假期间做了一下百度和西安交大联合举办的核心实体识别竞赛,最终的结果还不错,遂记录一下。模型的效果不是最好的,但是胜在“端到端”,迁移性强,估计对大家会有一定的参考价值。
比赛的主题是“核心实体识别”,其实有两个任务:核心识别 + 实体识别。这两个任务虽然有关联,但在传统自然语言处理程序中,一般是将它们分开处理的,而这次需要将两个任务联合在一起。如果只看“核心识别”,那就是传统的关键词抽取任务了,不同的是,传统的纯粹基于统计的思路(如TF-IDF抽取)是行不通的,因为单句中的核心实体可能就只出现一次,这时候统计估计是不可靠的,最好能够从语义的角度来理解。我一开始就是从“核心识别”入手,使用的方法类似QA系统:
1、将句子分词,然后用Word2Vec训练词向量;
2、用卷积神经网络(在这种抽取式问题上,CNN效果往往比RNN要好)卷积一下,得到一个与词向量维度一样的输出;
3、损失函数就是输出向量跟训练样本的核心词向量的cos值。
于是要找到句子的核心词,我只需要给每个句子计算一个输出向量,然后比较它与句子中每个词的向量的cos值,降序排列就行了。这个方法的明显优势是运行速度很快。最终,我用这个模型在公开评测集上做到了0.35的准确率,后来感觉难以提升,就放弃了这个思路。
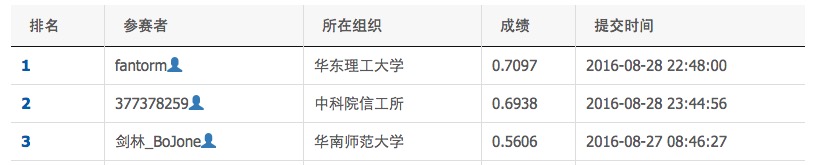
膜拜0.7的大神
为什么放弃?事实上,这个思路在“核心识别”这部分做得很好,但它的致命缺陷就是:它依赖于分词效果。分词系统往往会把一些长词构成的核心实体切开,比如“朱家花园”切分为“朱家/花园”,切分后要进行整合就难得多了。于是,我参照《【中文分词系列】 4. 基于双向LSTM的seq2seq字标注》一文,用词标注的思路来做,因为这个思路不明显依赖于分词效果。最终我用这个思路做到了0.56的准确率。
大概步骤是:
1、将句子分词,然后用Word2Vec训练词向量;
2、将输出转化为5tag标注问题:b(核心实体首词)、m(核心实体中)、e(核心实体末词)、s(单词成核心实体)、x(非核心实体部分);
3、用双层双向LSTM进行预测,用viterbi算法进行标注。
最后,需要一提的是,根据这种思路,甚至可以不分词就来做核心实体识别,但总的来说,还是分了词的效果会好一些,并且分词有利于降低句子长度(100字的句子分词后变成50词的句子),这有利于减少模型的参数个数。这里我们只需要一个简单的分词系统即可,并且不需要它们内置的新词发现功能。
迁移学习 #
但是,用这个思路之前我是很不确定它最终的效果的。主要原因是:百度给出了1.2万的训练样本,但却有20万的测试样本。比例如此悬殊,效果似乎很难好起来。此外,有5个tag,其中相比x这个tag,其他四个tag的数量是很少的,只有1.2万的训练样本,似乎存在数据不充分的问题。
当然,实践是检验真理的唯一标准。这个思路的首次测试就达到了0.42的准确率,远高于我前面精心调节了大半个月的CNN思路,于是我就往这个思路继续做下去。在继续做下去之前,我分析了这种思路效果不错的原因。我觉得,主要原因有两个:一个是“迁移学习”,另外一个就是LSTM强大的捕捉语义的能力。
传统数据挖掘的训练模型,是纯粹在训练集上做的。但是我们很难保证,训练集跟测试集是一致的,准确来说,就是很难假设训练集和测试集的分布是一样的。于是乎,即使模型训练效果非常好,测试效果也可能一塌糊涂,这不是过拟合所致,这是训练集和测试集不一致所造成的。
解决(缓解)这个问题的一个思路就是“迁移学习”。迁移学习现在已经是比较综合的建模策略了,在此不详述。一般来说,它有两套方案:
1、在建模前迁移学习,即可以把训练集和测试集放在一起,来学习建模用到的特征,这样得来的特征已经包含了测试集的信息;
2、在建模后迁移学习,即如果测试集的测试效果还不错,比如0.5的准确率,想要提高准确率,可以把测试集连同它的预测结果一起,当做训练样本,跟原来的训练样本一起重新训练模型。
大家可能对第2点比较困惑,测试集的预测结果不是有错的吗?输入错误的结果还能提高准确率?托尔斯泰说过“幸福的家庭都是相似的,不幸的家庭各有各的不幸”,放到这里,我想说的是“正确的答案都是相同的,错误的答案各有各的不同”。也就是说,如果进行第2点训练,测试集中给出的正确答案,效果会累积,因为它们都是正确的(相同的)模式的出来的结果,但是错误的答案各有不同的错误模式,如果模型参数有限,不至于过拟合,那么模型就会抹平这些错误模式,从而倾向于正确的答案。当然,这个理解是否准确,请读者点评。另外,如果得到了新的预测结果,那么可以只取两次相同的预测结果作为训练样本,这样的正确答案的比例就更高了。
在这个比赛中,迁移学习体现在:
1、用训练语料和测试语料一起训练Word2Vec,使得词向量本捕捉了测试语料的语义;
2、用训练语料训练模型;
3、得到模型后,对测试语料预测,把预测结果跟训练语料一起训练新的模型;
4、用新的模型预测,模型效果会有一定提升;
5、对比两次预测结果,如果两次预测结果都一样,那说明这个预测结果很有可能是对的,用这部分“很有可能是对的”的测试结果来训练模型;
6、用更新的模型预测;
7、如果你愿意,可以继续重复第4、5、6步。
双向LSTM #
主要的模型结构:
'''
用最新版本的Keras训练模型,使用GPU加速(我的是GTX 960)
其中Bidirectional函数目前要在github版本才有
'''
from keras.layers import Dense, LSTM, Lambda, TimeDistributed, Input, Masking, Bidirectional
from keras.models import Model
from keras.utils import np_utils
from keras.regularizers import activity_l1 #通过L1正则项,使得输出更加稀疏
sequence = Input(shape=(maxlen, word_size))
mask = Masking(mask_value=0.)(sequence)
blstm = Bidirectional(LSTM(64, return_sequences=True), merge_mode='sum')(mask)
blstm = Bidirectional(LSTM(32, return_sequences=True), merge_mode='sum')(blstm)
output = TimeDistributed(Dense(5, activation='softmax', activity_regularizer=activity_l1(0.01)))(blstm)
model = Model(input=sequence, output=output)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
就是用了双层的双向LSTM(单层我也试过,多加一层效果好一些),保留LSTM每次的输出,然后对每个输出都做一下softmax,整个过程基本就是分词系统一样了。
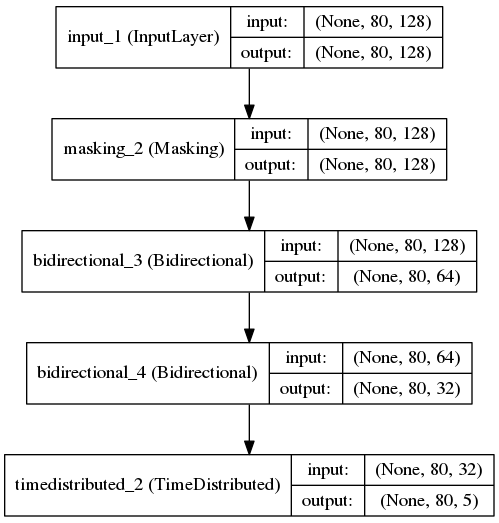
model
当然,这个模型的好坏,很大程度上还取决于词向量的质量。经过多次调试,我发现如下的词向量参数基本是最优的:
word2vec = gensim.models.Word2Vec(dd['words'].append(d['words']),
min_count=1,
size=word_size,
workers=20,
iter=20,
window=8,
negative=8,
sg=1)
也就是说,skip-gram的效果要比cbow要好,负样本采样的模式要比层次softmax要好,负样本的数目要适中,窗口大小也要适中。当然,这个所谓的“最优”,是多次人工调试后,我自己“直观感觉”的,欢迎大家做更多的测试。
关于比赛 #
百度跟西安交大这个比赛其实去年我也留意到了,但是我去年还是菜鸟水平,没法做那么艰难的任务。今年尝试做了一下,感觉收获颇丰的。
首先,比赛是百度举行的,单凭这点已经很有吸引力了,因为通常感觉如果能得到百度的肯定,那是一件了不起的事情,所以挺期待这类比赛的(希望有时间参加吧),也希望百度的比赛越办越好哈(套话了~)。其次,在这个过程中,我对语言模型的例子、深度网络的搭建与使用等,都有了更加深入的认识了,比如CNN怎么用于语言任务、可以用于哪些语言任务,还有seq2seq的初步使用等。
很碰巧的是,这次是一个自然语言处理任务,上次泰迪杯是一个图像任务,两次加起来,我把自然语言处理和图像的基本任务都做了一遍,心里对这些任务的处理都比较有底了,感觉挺踏实的。
完整代码 #
训练集链接: https://pan.baidu.com/s/1i457nkL 密码: stkp
说明文件
基于迁移学习和双向LSTM的核心实体识别
==============================================================
总的步骤(在train_and_predict.py中一一对应)
==============================================================1、训练语料和测试语料都分词,目前用的是结巴分词;
2、转化为5tag标注问题,构建训练标签;
3、训练语料和测试语料一起训练Word2Vec模型;
4、用双层双向LSTM训练标注模型,基于seq2seq的思想;
5、用模型进行预测,预测准确率大约会在0.46~0.52波动;
6、将预测结果当作标签数据,与训练数据一起,重新训练模型;
7、用新模型预测,预测准确率会在0.5~0.55波动;
8、比较两次预测结果,取交集当做标签数据,与训练数据一起,重新训练模型;
9、用新模型预测,预测准确率基本保持在0.53~0.56。==============================================================
编译环境:
==============================================================硬件环境:
1、96G内存(事实上用到10G左右)
2、GTX960显卡(GPU加速训练)软件环境:
1、CentOS 7
2、Python 2.7(以下均为Python第三方库)
3、结巴分词
4、Numpy
5、SciPy
6、Pandas
7、Keras(官方GitHub版本)
8、Gensim
9、H5PY
10、tqdm==============================================================
文件使用说明:
==============================================================train_and_predict.py
包含了从训练到预测的整个过程,只要“未开放的验证数据”格式跟“开放的测试数据”opendata_20w格式一样,那么就可以
与train_and_predict.py放在同一目录,然后运行
python train_and_predict.py
就可以完成整个过程,并且会生成一系列文件:--------------------------------------------------------------
word2vec_words_final.model,word2vec模型words_seq2seq_final_1.model,首次得到的双层双向LSTM模型
--- result1.txt,首次预测结果文件
--- result1.zip,首次预测结果文件压缩包words_seq2seq_final_2.model,通过第一次迁移学习后得到的模型
--- result2.txt,再次预测结果文件
--- result2.zip,再次预测结果文件压缩包words_seq2seq_final_3.model,通过第二次迁移学习后得到的模型
--- result3.txt,再次预测结果文件
--- result3.zip,再次预测结果文件压缩包words_seq2seq_final_4.model,通过第三次迁移学习后得到的模型
--- result4.txt,再次预测结果文件
--- result4.zip,再次预测结果文件压缩包words_seq2seq_final_5.model,通过第四次迁移学习后得到的模型
--- result5.txt,再次预测结果文件
--- result5.zip,再次预测结果文件压缩包
---------------------------------------------------------------==============================================================
思路说明:
==============================================================迁移学习体现在:
1、用训练语料和测试语料一起训练Word2Vec,使得词向量本捕捉了测试语料的语义;
2、用训练语料训练模型;
3、得到模型后,对测试语料预测,把预测结果跟训练语料一起训练新的模型;
4、用新的模型预测,模型效果会有一定提升;
5、对比两次预测结果,如果两次预测结果都一样,那说明这个预测结果很有可能是对的,用这部分“很有可能是对的”的测试结果来训练模型;
6、用更新的模型预测;
7、如果你愿意,可以继续重复第4、5、6步。双向LSTM的思路:
1、分词;
2、转换为5tag标注问题(0:非核心实体,1:单词的核心实体,2:多词核心实体的首词,3:多词核心实体的中间部分,4:多词核心实体的末词);
3、通过双向LSTM,直接对输入句子输出预测标注序列;
4、通过viterbi算法来获得标注结果;
5、因为常规的LSTM存在后面的词比前面的词更重要的弊端,因此用双向LSTM。
train_and_predict.py(代码并没整理,仅供测试参考)
#! -*- coding:utf-8 -*-
'''
基于迁移学习和双向LSTM的核心实体识别
迁移学习体现在:
1、用训练语料和测试语料一起训练Word2Vec,使得词向量本捕捉了测试语料的语义;
2、用训练语料训练模型;
3、得到模型后,对测试语料预测,把预测结果跟训练语料一起训练新的模型;
4、用新的模型预测,模型效果会有一定提升;
5、对比两次预测结果,如果两次预测结果都一样,那说明这个预测结果很有可能是对的,用这部分“很有可能是对的”的测试结果来训练模型;
6、用更新的模型预测;
7、如果你愿意,可以继续重复第4、5、6步。
双向LSTM的思路:
1、分词;
2、转换为5tag标注问题(0:非核心实体,1:单词的核心实体,2:多词核心实体的首词,3:多词核心实体的中间部分,4:多词核心实体的末词);
3、通过双向LSTM,直接对输入句子输出预测标注序列;
4、通过viterbi算法来获得标注结果;
5、因为常规的LSTM存在后面的词比前面的词更重要的弊端,因此用双向LSTM。
'''
import numpy as np
import pandas as pd
import jieba
from tqdm import tqdm
import re
d = pd.read_json('data.json') #训练数据已经被预处理成为标准json格式
d.index = range(len(d)) #重新定义一下索引,当然这只是优化显示效果
word_size = 128 #词向量维度
maxlen = 80 #句子截断长度
'''
修改分词函数,主要是:
1、英文和数字部分不分词,直接返回;
2、双书名号里边的内容不分词;
3、双引号里边如果是十字以内的内容不分词;
4、超出范围内的字符全部替换为空格;
5、分词使用结巴分词,并关闭新词发现功能。
'''
not_cuts = re.compile(u'([\da-zA-Z \.]+)|《(.*?)》|“(.{1,10})”')
re_replace = re.compile(u'[^\u4e00-\u9fa50-9a-zA-Z《》\(\)()“”·\.]')
def mycut(s):
result = []
j = 0
s = re_replace.sub(' ', s)
for i in not_cuts.finditer(s):
result.extend(jieba.lcut(s[j:i.start()], HMM=False))
if s[i.start()] in [u'《', u'“']:
result.extend([s[i.start()], s[i.start()+1:i.end()-1], s[i.end()-1]])
else:
result.append(s[i.start():i.end()])
j = i.end()
result.extend(jieba.lcut(s[j:], HMM=False))
return result
d['words'] = d['content'].apply(mycut) #分词
def label(k): #将输出结果转换为标签序列
s = d['words'][k]
r = ['0']*len(s)
for i in range(len(s)):
for j in d['core_entity'][k]:
if s[i] in j:
r[i] = '1'
break
s = ''.join(r)
r = [0]*len(s)
for i in re.finditer('1+', s):
if i.end() - i.start() > 1:
r[i.start()] = 2
r[i.end()-1] = 4
for j in range(i.start()+1, i.end()-1):
r[j] = 3
else:
r[i.start()] = 1
return r
d['label'] = map(label, tqdm(iter(d.index))) #输出tags
#随机打乱数据
idx = range(len(d))
d.index = idx
np.random.shuffle(idx)
d = d.loc[idx]
d.index = range(len(d))
#读入测试数据并进行分词
dd = open('opendata_20w').read().decode('utf-8').split('\n')
dd = pd.DataFrame([dd]).T
dd.columns = ['content']
dd = dd[:-1]
print u'测试语料分词中......'
dd['words'] = dd['content'].apply(mycut)
'''
用gensim来训练Word2Vec:
1、联合训练语料和测试语料一起训练;
2、经过测试用skip gram效果会好些。
'''
import gensim, logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
word2vec = gensim.models.Word2Vec(dd['words'].append(d['words']),
min_count=1,
size=word_size,
workers=20,
iter=20,
window=8,
negative=8,
sg=1)
word2vec.save('word2vec_words_final.model')
word2vec.init_sims(replace=True) #预先归一化,使得词向量不受尺度影响
print u'正在进行第一次训练......'
'''
用最新版本的Keras训练模型,使用GPU加速(我的是GTX 960)
其中Bidirectional函数目前要在github版本才有
'''
from keras.layers import Dense, LSTM, Lambda, TimeDistributed, Input, Masking, Bidirectional
from keras.models import Model
from keras.utils import np_utils
from keras.regularizers import activity_l1 #通过L1正则项,使得输出更加稀疏
sequence = Input(shape=(maxlen, word_size))
mask = Masking(mask_value=0.)(sequence)
blstm = Bidirectional(LSTM(64, return_sequences=True), merge_mode='sum')(mask)
blstm = Bidirectional(LSTM(32, return_sequences=True), merge_mode='sum')(blstm)
output = TimeDistributed(Dense(5, activation='softmax', activity_regularizer=activity_l1(0.01)))(blstm)
model = Model(input=sequence, output=output)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
'''
gen_matrix实现从分词后的list来输出训练样本
gen_target实现将输出序列转换为one hot形式的目标
超过maxlen则截断,不足补0
'''
gen_matrix = lambda z: np.vstack((word2vec[z[:maxlen]], np.zeros((maxlen-len(z[:maxlen]), word_size))))
gen_target = lambda z: np_utils.to_categorical(np.array(z[:maxlen] + [0]*(maxlen-len(z[:maxlen]))), 5)
#从节省内存的角度,通过生成器的方式来训练
def data_generator(data, targets, batch_size):
idx = np.arange(len(data))
np.random.shuffle(idx)
batches = [idx[range(batch_size*i, min(len(data), batch_size*(i+1)))] for i in range(len(data)/batch_size+1)]
while True:
for i in batches:
xx, yy = np.array(map(gen_matrix, data[i])), np.array(map(gen_target, targets[i]))
yield (xx, yy)
batch_size = 1024
history = model.fit_generator(data_generator(d['words'], d['label'], batch_size), samples_per_epoch=len(d), nb_epoch=200)
model.save_weights('words_seq2seq_final_1.model')
#输出预测结果(原始数据,未整理)
def predict_data(data, batch_size):
batches = [range(batch_size*i, min(len(data), batch_size*(i+1))) for i in range(len(data)/batch_size+1)]
p = model.predict(np.array(map(gen_matrix, data[batches[0]])), verbose=1)
for i in batches[1:]:
print min(i), 'done.'
p = np.vstack((p, model.predict(np.array(map(gen_matrix, data[i])), verbose=1)))
return p
d['predict'] = list(predict_data(d['words'], batch_size))
dd['predict'] = list(predict_data(dd['words'], batch_size))
'''
动态规划部分:
1、zy是转移矩阵,用了对数概率;概率的数值是大概估计的,事实上,这个数值的精确意义不是很大。
2、viterbi是动态规划算法。
'''
zy = {'00':0.15,
'01':0.15,
'02':0.7,
'10':1.0,
'23':0.5,
'24':0.5,
'33':0.5,
'34':0.5,
'40':1.0
}
zy = {i:np.log(zy[i]) for i in zy.keys()}
def viterbi(nodes):
paths = nodes[0]
for l in range(1,len(nodes)):
paths_ = paths.copy()
paths = {}
for i in nodes[l].keys():
nows = {}
for j in paths_.keys():
if j[-1]+i in zy.keys():
nows[j+i]= paths_[j]+nodes[l][i]+zy[j[-1]+i]
k = np.argmax(nows.values())
paths[nows.keys()[k]] = nows.values()[k]
return paths.keys()[np.argmax(paths.values())]
'''
整理输出结果,即生成提交数据所需要的格式。
整个过程包括:动态规划、结果提取。
'''
def predict(i):
nodes = [dict(zip(['0','1','2','3','4'], k)) for k in np.log(dd['predict'][i][:len(dd['words'][i])])]
r = viterbi(nodes)
result = []
words = dd['words'][i]
for j in re.finditer('2.*?4|1', r):
result.append((''.join(words[j.start():j.end()]), np.mean([nodes[k][r[k]] for k in range(j.start(),j.end())])))
if result:
result = pd.DataFrame(result)
return [result[0][result[1].argmax()]]
else:
return result
dd['core_entity'] = map(predict, tqdm(iter(dd.index), desc=u'第一次预测'))
'''
导出提交的JSON格式
'''
gen = lambda i:'[{"content": "'+dd.iloc[i]['content']+'", "core_entity": ["'+''.join(dd.iloc[i]['core_entity'])+'"]}]'
ssss = map(gen, tqdm(range(len(dd))))
result='\n'.join(ssss)
import codecs
f=codecs.open('result1.txt', 'w', encoding='utf-8')
f.write(result)
f.close()
import os
os.system('rm result1.zip')
os.system('zip result1.zip result1.txt')
print u'正在进行第一次迁移学习......'
'''
开始迁移学习。
'''
def label(k): #将输出结果转换为标签序列
s = dd['words'][k]
r = ['0']*len(s)
for i in range(len(s)):
for j in dd['core_entity'][k]:
if s[i] in j:
r[i] = '1'
break
s = ''.join(r)
r = [0]*len(s)
for i in re.finditer('1+', s):
if i.end() - i.start() > 1:
r[i.start()] = 2
r[i.end()-1] = 4
for j in range(i.start()+1, i.end()-1):
r[j] = 3
else:
r[i.start()] = 1
return r
dd['label'] = map(label, tqdm(iter(dd.index))) #输出tags
'''
将测试集和训练集一起放到模型中训练,
其中测试集的样本权重设置为1,训练集为10
'''
w = np.array([1]*len(dd) + [10]*len(d))
def data_generator(data, targets, batch_size):
idx = np.arange(len(data))
np.random.shuffle(idx)
batches = [idx[range(batch_size*i, min(len(data), batch_size*(i+1)))] for i in range(len(data)/batch_size+1)]
while True:
for i in batches:
xx, yy = np.array(map(gen_matrix, data[i])), np.array(map(gen_target, targets[i]))
yield (xx, yy, w[i])
history = model.fit_generator(data_generator(
dd[['words']].append(d[['words']], ignore_index=True)['words'],
dd[['label']].append(d[['label']], ignore_index=True)['label'],
batch_size),
samples_per_epoch=len(dd)+len(d),
nb_epoch=20)
model.save_weights('words_seq2seq_final_2.model')
d['predict'] = list(predict_data(d['words'], batch_size))
dd['predict'] = list(predict_data(dd['words'], batch_size))
dd['core_entity_2'] = map(predict, tqdm(iter(dd.index), desc=u'第一次迁移学习预测'))
'''
导出提交的JSON格式
'''
gen = lambda i:'[{"content": "'+dd.iloc[i]['content']+'", "core_entity": ["'+''.join(dd.iloc[i]['core_entity_2'])+'"]}]'
ssss = map(gen, tqdm(range(len(dd))))
result='\n'.join(ssss)
import codecs
f=codecs.open('result2.txt', 'w', encoding='utf-8')
f.write(result)
f.close()
import os
os.system('rm result2.zip')
os.system('zip result2.zip result2.txt')
print u'正在进行第二次迁移学习......'
'''
开始迁移学习2。
'''
ddd = dd[dd['core_entity'] == dd['core_entity_2']].copy()
'''
将测试集和训练集一起放到模型中训练,
其中测试集的样本权重设置为1,训练集为5
'''
w = np.array([1]*len(ddd) + [5]*len(d))
def data_generator(data, targets, batch_size):
idx = np.arange(len(data))
np.random.shuffle(idx)
batches = [idx[range(batch_size*i, min(len(data), batch_size*(i+1)))] for i in range(len(data)/batch_size+1)]
while True:
for i in batches:
xx, yy = np.array(map(gen_matrix, data[i])), np.array(map(gen_target, targets[i]))
yield (xx, yy, w[i])
history = model.fit_generator(data_generator(
ddd[['words']].append(d[['words']], ignore_index=True)['words'],
ddd[['label']].append(d[['label']], ignore_index=True)['label'],
batch_size),
samples_per_epoch=len(ddd)+len(d),
nb_epoch=20)
model.save_weights('words_seq2seq_final_3.model')
d['predict'] = list(predict_data(d['words'], batch_size))
dd['predict'] = list(predict_data(dd['words'], batch_size))
dd['core_entity_3'] = map(predict, tqdm(iter(dd.index), desc=u'第二次迁移学习预测'))
'''
导出提交的JSON格式
'''
gen = lambda i:'[{"content": "'+dd.iloc[i]['content']+'", "core_entity": ["'+''.join(dd.iloc[i]['core_entity_3'])+'"]}]'
ssss = map(gen, tqdm(range(len(dd))))
result='\n'.join(ssss)
import codecs
f=codecs.open('result3.txt', 'w', encoding='utf-8')
f.write(result)
f.close()
import os
os.system('rm result3.zip')
os.system('zip result3.zip result3.txt')
print u'正在进行第三次迁移学习......'
'''
开始迁移学习3。
'''
ddd = dd[dd['core_entity'] == dd['core_entity_2']].copy()
ddd = ddd[ddd['core_entity_3'] == ddd['core_entity_2']].copy()
'''
将测试集和训练集一起放到模型中训练,
其中测试集的样本权重设置为1,训练集为1
'''
w = np.array([1]*len(ddd) + [1]*len(d))
def data_generator(data, targets, batch_size):
idx = np.arange(len(data))
np.random.shuffle(idx)
batches = [idx[range(batch_size*i, min(len(data), batch_size*(i+1)))] for i in range(len(data)/batch_size+1)]
while True:
for i in batches:
xx, yy = np.array(map(gen_matrix, data[i])), np.array(map(gen_target, targets[i]))
yield (xx, yy, w[i])
history = model.fit_generator(data_generator(
ddd[['words']].append(d[['words']], ignore_index=True)['words'],
ddd[['label']].append(d[['label']], ignore_index=True)['label'],
batch_size),
samples_per_epoch=len(ddd)+len(d),
nb_epoch=20)
model.save_weights('words_seq2seq_final_4.model')
d['predict'] = list(predict_data(d['words'], batch_size))
dd['predict'] = list(predict_data(dd['words'], batch_size))
dd['core_entity_4'] = map(predict, tqdm(iter(dd.index), desc=u'第三次迁移学习预测'))
'''
导出提交的JSON格式
'''
gen = lambda i:'[{"content": "'+dd.iloc[i]['content']+'", "core_entity": ["'+''.join(dd.iloc[i]['core_entity_4'])+'"]}]'
ssss = map(gen, tqdm(range(len(dd))))
result='\n'.join(ssss)
import codecs
f=codecs.open('result4.txt', 'w', encoding='utf-8')
f.write(result)
f.close()
import os
os.system('rm result4.zip')
os.system('zip result4.zip result4.txt')
print u'正在进行第四次迁移学习......'
'''
开始迁移学习4。
'''
ddd = dd[dd['core_entity'] == dd['core_entity_2']].copy()
ddd = ddd[ddd['core_entity_3'] == ddd['core_entity_2']].copy()
ddd = ddd[ddd['core_entity_4'] == ddd['core_entity_2']].copy()
'''
将测试集和训练集一起放到模型中训练,
其中测试集的样本权重设置为1,训练集为1
'''
w = np.array([1]*len(ddd) + [1]*len(d))
def data_generator(data, targets, batch_size):
idx = np.arange(len(data))
np.random.shuffle(idx)
batches = [idx[range(batch_size*i, min(len(data), batch_size*(i+1)))] for i in range(len(data)/batch_size+1)]
while True:
for i in batches:
xx, yy = np.array(map(gen_matrix, data[i])), np.array(map(gen_target, targets[i]))
yield (xx, yy, w[i])
history = model.fit_generator(data_generator(
ddd[['words']].append(d[['words']], ignore_index=True)['words'],
ddd[['label']].append(d[['label']], ignore_index=True)['label'],
batch_size),
samples_per_epoch=len(ddd)+len(d),
nb_epoch=20)
model.save_weights('words_seq2seq_final_5.model')
d['predict'] = list(predict_data(d['words'], batch_size))
dd['predict'] = list(predict_data(dd['words'], batch_size))
dd['core_entity_5'] = map(predict, tqdm(iter(dd.index), desc=u'第四次迁移学习预测'))
'''
导出提交的JSON格式
'''
gen = lambda i:'[{"content": "'+dd.iloc[i]['content']+'", "core_entity": ["'+''.join(dd.iloc[i]['core_entity_5'])+'"]}]'
ssss = map(gen, tqdm(range(len(dd))))
result='\n'.join(ssss)
import codecs
f=codecs.open('result5.txt', 'w', encoding='utf-8')
f.write(result)
f.close()
import os
os.system('rm result5.zip')
os.system('zip result5.zip result5.txt')
转载到请包括本文地址:https://www.spaces.ac.cn/archives/3942
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Sep. 06, 2016). 《基于双向LSTM和迁移学习的seq2seq核心实体识别 》[Blog post]. Retrieved from https://www.spaces.ac.cn/archives/3942
@online{kexuefm-3942,
title={基于双向LSTM和迁移学习的seq2seq核心实体识别},
author={苏剑林},
year={2016},
month={Sep},
url={\url{https://www.spaces.ac.cn/archives/3942}},
}

September 10th, 2016
很感谢您的分享。不过,实验的的测试数据貌似网上找不到了,请问你可以分享下吗?
可以QQ联系我
我上传了一份,https://pan.baidu.com/s/1qYldsLm
您好,搜双向LSTM搜到了这篇博文,对我非常有启发,觉得这个问题还蛮有趣的,然而去看了看百度的页面,训练数据好像已经被度娘取消分享了,请问 lz 是否可以也顺便分享一下训练数据?非常感谢。
September 28th, 2016
思路和模型很新,不过准确率还应用不了,学习一下^.^
December 1st, 2016
您好,很感谢您的分享。想请问下,测试集的结果没有提供文件,也就是说没有办法看准确率了对吗?
目前没办法啦,之前是百度自己的评测榜上的。后来他也没公开数据。
December 22nd, 2016
楼主您好,看了你很多po的文章,确实很详尽,有创新点,有些东西还想问一下,比如用深度学习进行文本分类,中文分词以及情感分析,或者使用word2vec进行相关的操作和验证,是否可以分享一下,我的qq是812093147,望加&讨论
博客里已经有不少文章探讨这些问题了,思路有、代码也有,你要怎样的分享?
February 20th, 2017
非常感谢分享,现在训练集数据也不能下载,可否分享一下.
私下联系吧。
您好,感谢您对思路和代码详尽和细致的分享,我已经拿到了测试数据,但是还是找不到训练集数据(在github上也没有找到...),所有能否麻烦您发送我一份训练集数据,我的邮箱felix_h_huang@hotmail.com。谢谢!
May 23rd, 2017
楼主,你好,看了你好几篇文章,写得很详尽,学习了很多。
想问问你能否分享一下训练数据和测试数据呀~(我的邮箱kl11384517@163.com)
万分感谢~
文末已经分享了训练集,测试集我也没有了。不过测试集没有标签的,就是无标签的语料而已。
对哈 测试数据不会有标签 是我疏漏了 多谢楼主啦~ 谢谢~
October 28th, 2017
楼主你好,请问把annotated的测试集(尽管有错误)也加入训练集之后再训练测试集的结果有多少提升呢?
然后,请问有没有这样做法的paper可以看呢?
谢谢!
November 2nd, 2017
两个BLSTM之间不需要加个linear吗 参见CRNN。
一般的层叠rnn都好像没有加的呀
November 13th, 2017
楼主,你好,看了你的文章,收益很大,可是运行您的代码的时候之前会出现ValueError: output of generator should be a tuple `(x, y, sample_weight)` or `(x, y)`. Found: None的错误,修改data_generator这个函数后,直接运行data_generator这个函数并不会报错(都是有输出的),但是用模型训练数据时调用该函数却会报错(如下),感觉很奇怪,不知道为啥会出现这个情况,输入的数据都有呀~~~希望能够得到楼主的解答
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
in ()
63 # print("data_generator(d['words'], d['label'], batch_size)")
64 # print(data_generator(d['words'], d['label'], batch_size))
---> 65 history = model.fit_generator(data_generator(d['words'], d['label'], batch_size),samples_per_epoch=len(d), nb_epoch=200)
66 model.save_weights('words_seq2seq_final_1.model')
67
/usr/local/lib/python3.5/dist-packages/keras/legacy/interfaces.py in wrapper(*args, **kwargs)
86 warnings.warn('Update your `' + object_name +
87 '` call to the Keras 2 API: ' + signature, stacklevel=2)
---> 88 return func(*args, **kwargs)
89 wrapper._legacy_support_signature = inspect.getargspec(func)
90 return wrapper
/usr/local/lib/python3.5/dist-packages/keras/engine/training.py in fit_generator(self, generator, steps_per_epoch, epochs, verbose, callbacks, validation_data, validation_steps, class_weight, max_q_size, workers, pickle_safe, initial_epoch)
1881 batch_size = list(x.values())[0].shape[0]
1882 else:
-> 1883 batch_size = x.shape[0]
1884 batch_logs['batch'] = batch_index
1885 batch_logs['size'] = batch_size
IndexError: tuple index out of range
感觉是generator运行过程中出了问题,你用Python x.x?
♪(^∀^●)ノ楼主您好,已经找到问题所在:
因为用的python3.5,之前老是报错我就想跳过生成器直接用一般的model.fit,就会报错'map object is not subscriptable',所以才发现是因为‘在Python2中map函数会返回一个list列表;而在Python3中会返回’⊙﹏⊙‖∣~~然后把所有的map前面都加了list就可以运行了♪(^∀^●)ノ
不过还是很开心得到楼主的回复♪(^∀^●)ノ谢谢哒
如果可以希望能够得到楼主的邮件联系方式,希望以后能跟楼主多多请教♪(^∀^●)ノ
解决问题就好^_^
November 13th, 2017
博主你好,对核心实体识别时,我看您的方法还是一个基于字标注的方法。我想请问一下,既然是字标注的话,为什么还要训练词向量呢
本文是基于词标注的。
此外,就算是字标注,也要预训练字向量,因为训练集和测试集比例相差太大(1:20)
是训练字向量?不是词向量?