






 感谢国家天文台LAMOST项目之“宇宙驿站”提供网络空间和数据库资源! 感谢国家天文台崔辰州博士等人的多方努力和技术支持!
感谢国家天文台LAMOST项目之“宇宙驿站”提供网络空间和数据库资源! 感谢国家天文台崔辰州博士等人的多方努力和技术支持! 科学空间致力于知识分享,所以欢迎您转载本站文章,但转载本站内容必须遵循 署名-非商业用途-保持一致 的创作共用协议。
科学空间致力于知识分享,所以欢迎您转载本站文章,但转载本站内容必须遵循 署名-非商业用途-保持一致 的创作共用协议。
7
Feb
你的CRF层的学习率可能不够大
By 苏剑林 | 2020-02-07 | 141259位读者 | Kimi 引用CRF是做序列标注的经典方法,它理论优雅,实际也很有效,如果还不了解CRF的读者欢迎阅读旧作《简明条件随机场CRF介绍(附带纯Keras实现)》。在BERT模型出来之后,也有不少工作探索了BERT+CRF用于序列标注任务的做法。然而,很多实验结果显示(比如论文《BERT Meets Chinese Word Segmentation》)不管是中文分词还是实体识别任务,相比于简单的BERT+Softmax,BERT+CRF似乎并没有带来什么提升,这跟传统的BiLSTM+CRF或CNN+CRF的模型表现并不一样。
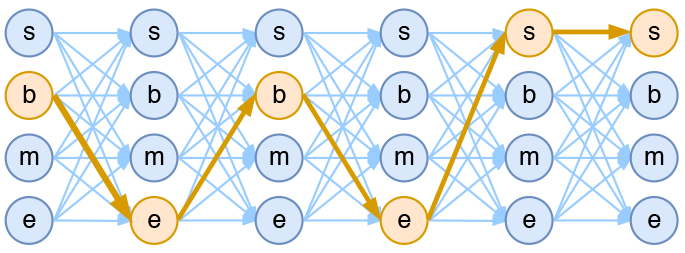
基于CRF的4标签分词模型示意图
这两天给bert4keras增加了用CRF做中文分词的例子(task_sequence_labeling_cws_crf.py),在调试过程中发现了CRF层可能存在学习不充分的问题,进一步做了几个对比实验,结果显示这可能是CRF在BERT中没什么提升的主要原因,遂在此记录一下分析过程,与大家分享。
29
Jan
抛开约束,增强模型:一行代码提升albert表现
By 苏剑林 | 2020-01-29 | 105047位读者 | Kimi 引用
16
Jan
从几何视角来理解模型参数的初始化策略
By 苏剑林 | 2020-01-16 | 153919位读者 | Kimi 引用对于复杂模型来说,参数的初始化显得尤为重要。糟糕的初始化,很多时候已经不单是模型效果变差的问题了,还更有可能是模型根本训练不动或者不收敛。在深度学习中常见的自适应初始化策略是Xavier初始化,它是从正态分布$\mathcal{N}\left(0,\frac{2}{fan_{in} + fan_{out}}\right)$中随机采样而构成的初始权重,其中$fan_{in}$是输入的维度而$fan_{out}$是输出的维度。其他初始化策略基本上也类似,只不过假设有所不同,导致最终形式略有差别。
标准的初始化策略的推导是基于概率统计的,大概的思路是假设输入数据的均值为0、方差为1,然后期望输出数据也保持均值为0、方差为1,然后推导出初始变换应该满足的均值和方差条件。这个过程理论上没啥问题,但在笔者看来依然不够直观,而且推导过程的假设有点多。本文则希望能从几何视角来理解模型的初始化方法,给出一个更直观的推导过程。
信手拈来的正交
前者时间笔者写了《n维空间下两个随机向量的夹角分布》,其中的一个推论是
推论1: 高维空间中的任意两个随机向量几乎都是垂直的。
12
Jan
Self-Orthogonality Module:一个即插即用的核正交化模块
By 苏剑林 | 2020-01-12 | 71315位读者 | Kimi 引用前些天刷Arxiv看到新文章《Self-Orthogonality Module: A Network Architecture Plug-in for Learning Orthogonal Filters》(下面简称“原论文”),看上去似乎有点意思,于是阅读了一番,读完确实有些收获,在此记录分享一下。
给全连接或者卷积模型的核加上带有正交化倾向的正则项,是不少模型的需求,比如大名鼎鼎的BigGAN就加入了类似的正则项。而这篇论文则引入了一个新的正则项,笔者认为整个分析过程颇为有趣,可以一读。
为什么希望正交?
在开始之前,我们先约定:本文所出现的所有一维向量都代表列向量。那么,现在假设有一个$d$维的输入样本$\boldsymbol{x}\in \mathbb{R}^d$,经过全连接或卷积层时,其核心运算就是:
\begin{equation}\boldsymbol{y}^{\top}=\boldsymbol{x}^{\top}\boldsymbol{W},\quad \boldsymbol{W}\triangleq (\boldsymbol{w}_1,\boldsymbol{w}_2,\dots,\boldsymbol{w}_k)\label{eq:k}\end{equation}
其中$\boldsymbol{W}\in \mathbb{R}^{d\times k}$是一个矩阵,它就被称“核”(全连接核/卷积核),而$\boldsymbol{w}_1,\boldsymbol{w}_2,\dots,\boldsymbol{w}_k\in \mathbb{R}^{d}$是该矩阵的各个列向量。
3
Jan
用bert4keras做三元组抽取
By 苏剑林 | 2020-01-03 | 352421位读者 | Kimi 引用在开发bert4keras的时候就承诺过,会逐渐将之前用keras-bert实现的例子逐渐迁移到bert4keras来,而那里其中一个例子便是三元组抽取的任务。现在bert4keras的例子已经颇为丰富了,但还没有序列标注和信息抽取相关的任务,而三元组抽取正好是这样的一个任务,因此就补充上去了。
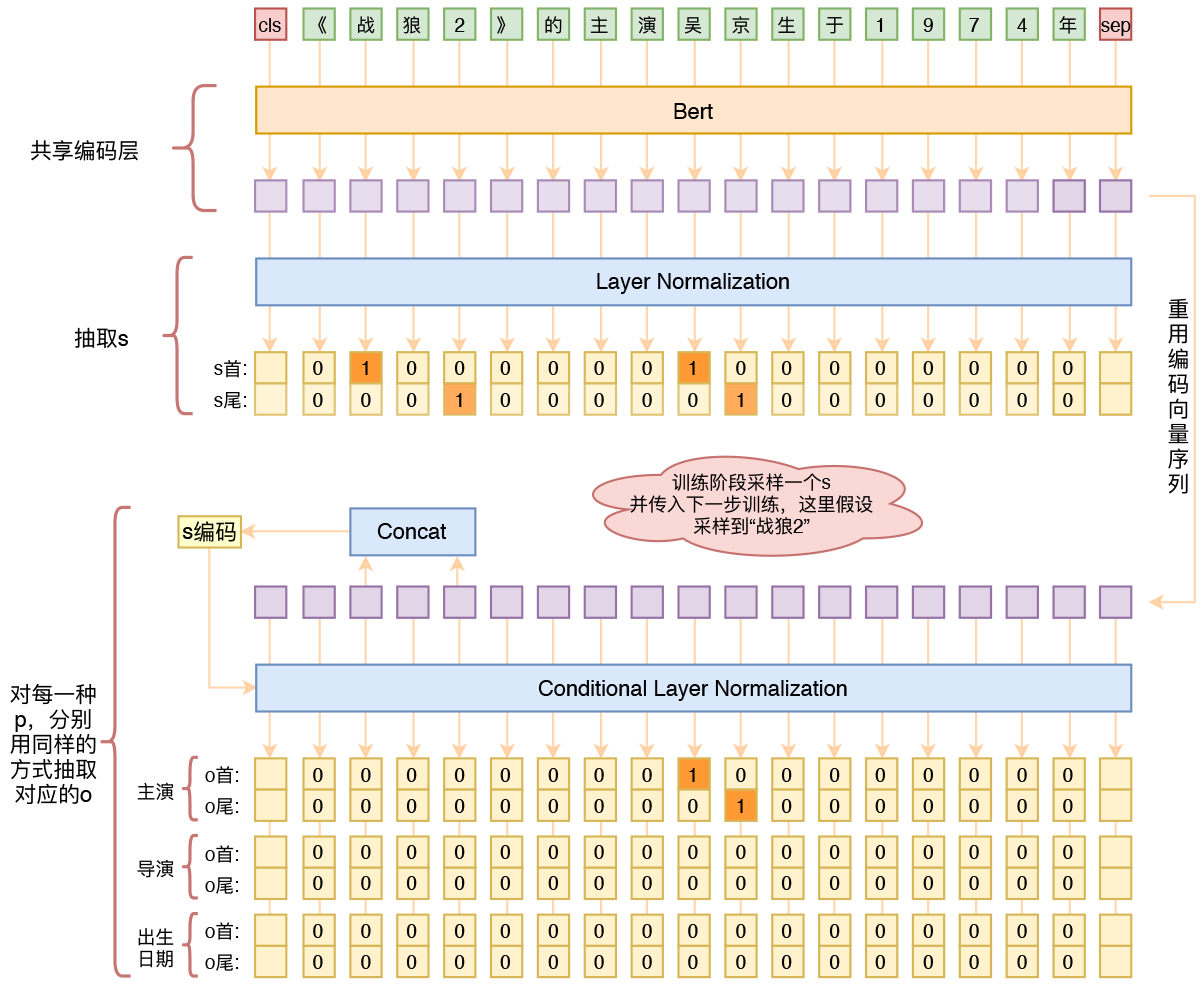
基于Bert的三元组抽取模型结构示意图
26
Dec
“非自回归”也不差:基于MLM的阅读理解问答
By 苏剑林 | 2019-12-26 | 109032位读者 | Kimi 引用![用MLM做阅读理解的模型图示(其中[M]表示[MASK]标记)](/usr/uploads/2019/12/1024911876.png)
14
Dec
基于Conditional Layer Normalization的条件文本生成
By 苏剑林 | 2019-12-14 | 153772位读者 | Kimi 引用从文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》中我们可以知道,只要配合适当的Attention Mask,Bert(或者其他Transformer模型)就可以用来做无条件生成(Language Model)和序列翻译(Seq2Seq)任务。
可如果是有条件生成呢?比如控制文本的类别,按类别随机生成文本,也就是Conditional Language Model;又比如传入一副图像,来生成一段相关的文本描述,也就是Image Caption。
相关工作
八月份的论文《Encoder-Agnostic Adaptation for Conditional Language Generation》比较系统地分析了利用预训练模型做条件生成的几种方案;九月份有一篇论文《CTRL: A Conditional Transformer Language Model for Controllable Generation》提供了一个基于条件生成来预训练的模型,不过这本质还是跟GPT一样的语言模型,只能以文字输入为条件;而最近的论文《Plug and Play Language Models: a Simple Approach to Controlled Text Generation》将$p(x|y)$转化为$p(x)p(y|x)$来探究基于预训练模型的条件生成。
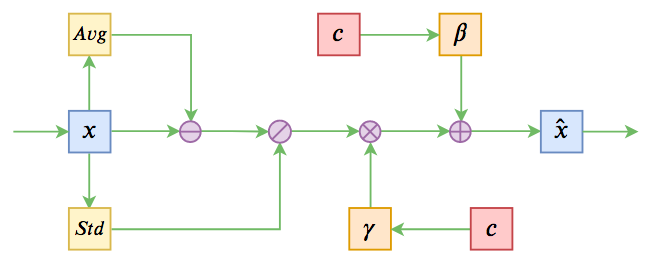
条件Normalization示意图
不过这些经典工作都不是本文要介绍的。本文关注的是以一个固定长度的向量作为条件的文本生成的场景,而方法是Conditional Layer Normalization——把条件融合到Layer Normalization的$\beta$和$\gamma$中去。

最近评论