






24
Jul
Monarch矩阵:计算高效的稀疏型矩阵分解
By 苏剑林 | 2024-07-24 | 1750位读者 | 引用在矩阵压缩这个问题上,我们通常有两个策略可以选择,分别是低秩化和稀疏化。低秩化通过寻找矩阵的低秩近似来减少矩阵尺寸,而稀疏化则是通过减少矩阵中的非零元素来降低矩阵的复杂性。如果说SVD是奔着矩阵的低秩近似去的,那么相应地寻找矩阵稀疏近似的算法又是什么呢?
接下来我们要学习的是论文《Monarch: Expressive Structured Matrices for Efficient and Accurate Training》,它为上述问题给出了一个答案——“Monarch矩阵”,这是一簇能够分解为若干置换矩阵与稀疏矩阵乘积的矩阵,同时具备计算高效且表达能力强的特点,论文还讨论了如何求一般矩阵的Monarch近似,以及利用Monarch矩阵参数化LLM来提高LLM速度等内容。
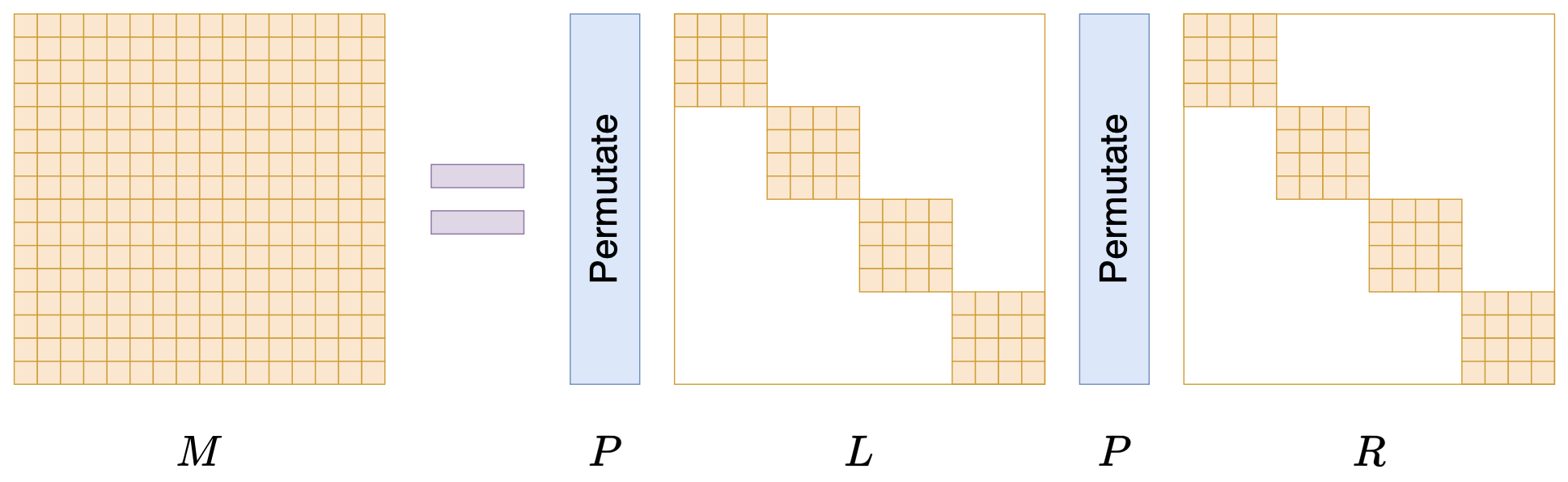
Monarch矩阵形式M=PLPR
值得指出的是,该论文的作者也正是著名的Flash Attention的作者Tri Dao,其工作几乎都在致力于改进LLM的性能,这篇Monarch也是他主页上特意展示的几篇论文之一,单从这一点看就非常值得学习一番。
13
May
缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA
By 苏剑林 | 2024-05-13 | 39172位读者 | 引用前几天,幻方发布的DeepSeek-V2引起了大家的热烈讨论。首先,最让人哗然的是1块钱100万token的价格,普遍比现有的各种竞品API便宜了两个数量级,以至于有人调侃“这个价格哪怕它输出乱码,我也会认为这个乱码是一种艺术”;其次,从模型的技术报告看,如此便宜的价格背后的关键技术之一是它新提出的MLA(Multi-head Latent Attention),这是对GQA的改进,据说能比GQA更省更好,也引起了读者的广泛关注。
接下来,本文将跟大家一起梳理一下从MHA、MQA、GQA到MLA的演变历程,并着重介绍一下MLA的设计思路。
MHA
MHA(Multi-Head Attention),也就是多头注意力,是开山之作《Attention is all you need》所提出的一种Attention形式,可以说它是当前主流LLM的基础工作。在数学上,多头注意力MHA等价于多个独立的单头注意力的拼接,假设输入的(行)向量序列为$\boldsymbol{x}_1,\boldsymbol{x}_2,\cdots,\boldsymbol{x}_l$,其中$\boldsymbol{x}_i\in\mathbb{R}^d$,那么MHA可以形式地记为
18
Mar
时空之章:将Attention视为平方复杂度的RNN
By 苏剑林 | 2024-03-18 | 32211位读者 | 引用近年来,RNN由于其线性的训练和推理效率,重新吸引了不少研究人员和用户的兴趣,隐约有“文艺复兴”之势,其代表作有RWKV、RetNet、Mamba等。当将RNN用于语言模型时,其典型特点就是每步生成都是常数的空间复杂度和时间复杂度,从整个序列看来就是常数的空间复杂度和线性的时间复杂度。当然,任何事情都有两面性,相比于Attention动态增长的KV Cache,RNN的常数空间复杂度通常也让人怀疑记忆容量有限,在Long Context上的效果很难比得上Attention。
在这篇文章中,我们表明Causal Attention可以重写成RNN的形式,并且它的每一步生成理论上也能够以$\mathcal{O}(1)$的空间复杂度进行(代价是时间复杂度非常高,远超平方级)。这表明Attention的优势(如果有的话)是靠计算堆出来的,而不是直觉上的堆内存,它跟RNN一样本质上都是常数量级的记忆容量(记忆瓶颈)。
29
Nov
我在Performer中发现了Transformer-VQ的踪迹
By 苏剑林 | 2023-11-29 | 36484位读者 | 引用前些天我们在《VQ一下Key,Transformer的复杂度就变成线性了》介绍了“Transformer-VQ”,这是通过将Key序列做VQ(Vector Quantize)变换来实现Attention复杂度线性化的方案。诚然,Transformer-VQ提供了标准Attention到线性Attentino的一个非常漂亮的过渡,给人一种“大道至简”的美感,但熟悉VQ的读者应该能感觉到,当编码表大小或者模型参数量进一步增加时,VQ很可能会成为效果提升的瓶颈,因为它通过STE(Straight-Through Estimator)估计的梯度大概率是次优的(FSQ的实验结果也算是提供了一些佐证)。此外,Transformer-VQ为了使训练效率也线性化所做的梯度截断,也可能成为将来的效果瓶颈之一。
为此,笔者花了一些时间思考可以替代掉VQ的线性化思路。从Transformer-VQ的$\exp\left(QC^{\top}\right)$形式中,笔者联想到了Performer,继而“顺藤摸瓜”地发现原来Performer可以视为Soft版的Transformer-VQ。进一步地,笔者尝试类比Performer的推导方法来重新导出Transformer-VQ,为其后的优化提供一些参考结果。
8
Oct
预训练一下,Transformer的长序列成绩还能涨不少!
By 苏剑林 | 2023-10-08 | 32248位读者 | 引用作为LLM的主流模型架构,Transformer在各类任务上的总体表现都出色,大多数情况下,Transformer的槽点只是它的平方复杂度,而不是效果——除了一个名为Long Range Arena(下面简称LRA)的Benchmark。一直以来,LRA一直是线性RNN类模型的“主场”,与之相比Transformer在上面有明显的差距,以至于让人怀疑这是否就是Transformer的固有缺陷。
不过,近日论文《Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors》将这“缺失的一环”给补齐了。论文指出,缺乏预训练是Transformer在LRA上效果较差的主要原因,而所有架构都可以通过预训练获得一定的提升,Transformer的提升则更为明显。
旧背景
Long Range Arena(LRA)是长序列建模的一个Benchmark,提出自论文《Long Range Arena: A Benchmark for Efficient Transformers》,从论文标题就可以看出,LRA是为了测试各种Efficient版的Transformer而构建的,里边包含了多种类型的数据,序列长度从1k到16k不等,此前不少Efficient Transformer的工作也都在LRA进行了测试。虽然在代表性方面有些争议,但LRA依然不失为一个测试Efficient Transformer的长序列能力的经典Benchmark。
26
Sep
脑洞大开:非线性RNN居然也可以并行计算?
By 苏剑林 | 2023-09-26 | 39410位读者 | 引用近年来,线性RNN由于其可并行训练以及常数推理成本等特性,吸引了一定研究人员的关注(例如笔者之前写的《Google新作试图“复活”RNN:RNN能否再次辉煌?》),这让RNN在Transformer遍地开花的潮流中仍有“一席之地”。然而,目前看来这“一席之地”只属于线性RNN,因为非线性RNN无法高效地并行训练,所以在架构之争中是“心有余而力不足”。
不过,一篇名为《Parallelizing Non-Linear Sequential Models over the Sequence Length》的论文有不同的看法,它提出了一种迭代算法,宣传可以实现非线性RNN的并行训练!真有如此神奇?接下来我们一探究竟。
求不动点
原论文对其方法做了非常一般的介绍,而且其侧重点是PDE和ODE,这里我们直接从RNN入手。考虑常见的简单非线性RNN:
\begin{equation}x_t = \tanh(Ax_{t-1} + u_t)\label{eq:rnn}\end{equation}
13
Sep
大词表语言模型在续写任务上的一个问题及对策
By 苏剑林 | 2023-09-13 | 23912位读者 | 引用对于LLM来说,通过增大Tokenizer的词表来提高压缩率,从而缩短序列长度、降低解码成本,是大家都喜闻乐见的事情。毕竟增大词表只需要增大Embedding层和输出的Dense层,这部分增加的计算量几乎不可感知,但缩短序列长度之后带来的解码速度提升却是实打实的。当然,增加词表大小也可能会对模型效果带来一些负面影响,所以也不能无节制地增加词表大小。本文就来分析增大词表后语言模型在续写任务上会出现的一个问题,并提出参考的解决方案。
优劣分析
增加词表大小的好处是显而易见的。一方面,由于LLM是自回归的,它的解码会越来越慢,而“增大词表 → 提高压缩率 → 缩短序列长度”,换言之相同文本对应的tokens数变少了,也就是解码步数变少了,从而解码速度提升了;另一方面,语言模型的训练方式是Teacher Forcing,缩短序列长度能够缓解Teacher Forcing带来的Exposure Bias问题,从而可能提升模型效果。
20
Jul
语言模型输出端共享Embedding的重新探索
By 苏剑林 | 2023-07-20 | 21904位读者 | 引用预训练刚兴起时,在语言模型的输出端重用Embedding权重是很常见的操作,比如BERT、第一版的T5、早期的GPT,都使用了这个操作,这是因为当模型主干部分不大且词表很大时,Embedding层的参数量很可观,如果输出端再新增一个独立的同样大小的权重矩阵的话,会导致显存消耗的激增。不过随着模型参数规模的增大,Embedding层的占比相对变小了,加之《Rethinking embedding coupling in pre-trained language models》等研究表明共享Embedding可能会有些负面影响,所以现在共享Embedding的做法已经越来越少了。
本文旨在分析在共享Embedding权重时可能遇到的问题,并探索如何更有效地进行初始化和参数化。尽管共享Embedding看起来已经“过时”,但这依然不失为一道有趣的研究题目。

最近评论