






5
Dec
万能的seq2seq:基于seq2seq的阅读理解问答
By 苏剑林 | 2019-12-05 | 116847位读者 |今天给bert4keras新增加了一个例子:阅读理解式问答(task_reading_comprehension_by_seq2seq.py),语料跟之前一样,都是用WebQA和SogouQA,最终的得分在0.77左右(单模型,没精调)。
方法简述 #
由于这次主要目的是给bert4keras增加demo,因此效率就不是主要关心的目标了。这次的目标主要是通用性和易用性,所以用了最万能的方案——seq2seq来实现做阅读理解。
用seq2seq做的话,基本不用怎么关心模型设计,只要把篇章和问题拼接起来,然后预测答案就行了。此外,seq2seq的方案还自然地包括了判断篇章有无答案的方法,以及自然地导出一种多篇章投票的思路。总而言之,不考虑效率的话,seq2seq做阅读理解是一种相当优雅的方案。
这次实现seq2seq还是用UNILM的方案,如果还不了解的读者,可以先阅读《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》了解相应内容。
模型细节 #
用UNILM方案搭建一个seq2seq模型在bert4keras中基本就是一行代码的事情,所以这个例子的主要工作在并不在模型的建立上,而是在输入输出的处理上面。
输入格式 #
首先是输入,输入格式很简单,一张图可以表达清楚:
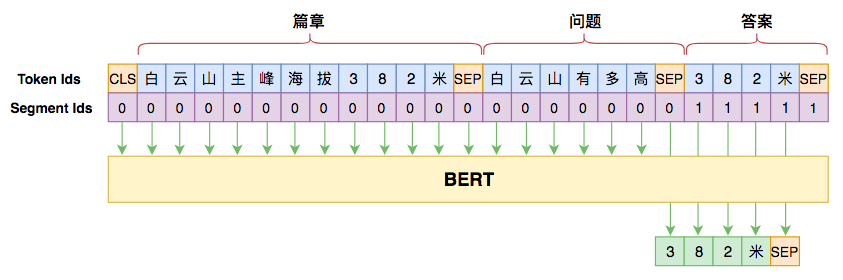
用seq2seq做阅读理解的模型图示
输出处理 #
如果输入单个篇章和单个问题进行回答,那么直接按照seq2seq常规的处理方案——即beam search——来解码即可。
但是,WebQA和SogouQA面对的是搜索场景,即同时存在多篇文章来对同一个问题进行回答,这就涉及到投票方案的选择了。一种朴素的思路是:每个篇章结合问题单独用beam search解码,并且给出置信度,最后再按照《基于CNN的阅读理解式问答模型:DGCNN》的投票方式进行。这种方式的困难之处在于对每个答案给出一个合理的置信度,它相比我们后面给出的思路则显得不够自然,并且效率也稍低些。
这里我们给出一种跟beam search更加“契合”的方案:
先排除没有答案的篇章,然后在解码答案的每一个字时,直接将所有篇章预测的概率值(按照某种方式)取平均。
具体来说,所有篇章分别和问题拼接起来,然后给出各自的第一个字的概率分布。那些第一个字就给出[SEP]的篇章意味着它是没有答案的,排除掉它们。排除掉之后,将剩下的篇章的第一个字的概率分布取平均,然后再保留topk(beam search的标准流程)。预测第二个字时,每个篇章与topk个候选值分别组合,预测各自的第二个字的概率分布,然后再按照篇章将概率平均后,再给出topk。依此类推,直到出现[SEP]。(其实就是在普通的beam search基础上加上按篇章平均,如果实在弄不明白,那就只能去看源码了~)
此外,生成答案的方式应该有两种,一种是抽取式的,这种模式下答案只能是篇章的一个片段,另外一种是生成式的,即不需要考虑答案是不是篇章的片段,直接解码生成答案即可。这两种方式在本文的解码中都有相应的判断处理。
实验代码 #
代码链接:task_reading_comprehension_by_seq2seq.py
最终在SogouQA自带的评估脚本上,valid集的分数大概是0.77 (Accuracy=0.7259005836184343,F1=0.813860036706151,Final=0.7698803101622926),单模型成绩远超过了之前的《开源一版DGCNN阅读理解问答模型(Keras版)》模型。当然,提升是有代价的——预测速度大大降低,每秒只能预测2条数据左右。
(模型没精细调优,估计还有提升空间,当前还是以demo为主。)
文章小结 #
本文主要是给出了一个基于bert和seq2seq思路的阅读理解例子,并且给出了一种多篇章投票的beam search策略,供读者参考和测试~
转载到请包括本文地址:https://www.spaces.ac.cn/archives/7115
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Dec. 05, 2019). 《万能的seq2seq:基于seq2seq的阅读理解问答 》[Blog post]. Retrieved from https://www.spaces.ac.cn/archives/7115
@online{kexuefm-7115,
title={万能的seq2seq:基于seq2seq的阅读理解问答},
author={苏剑林},
year={2019},
month={Dec},
url={\url{https://www.spaces.ac.cn/archives/7115}},
}

December 6th, 2019
苏神你好!感谢分享!
在应用中我尝试了一下用bert来生成seq2seq,与训练模型是用了wwm的,效果很不错,且生成的大意也相对准确。
但是我发现应用时,解码端解不到 结束符号 ,几乎每一个预测都解到不到结束符号。
然后我检查了我的输入输出对应关系,这些都没有搞错。
请问一下您有遇到这样的情况过吗?
谢谢!
没有遇到过
December 6th, 2019
这里去分布平均是什么意思
我认为文章已经说得清楚了。
如果还不明白,建议思考下面两个问题:
1、单输入、单输出的beam search弄清楚了吗?如果没有,请自行弄清楚。
2、多篇章来回答同一个问题,属于多输入、单输出的问题。本来单输入、单输出时就给出了一个概率分布了,现在是多输入,自然有多个分布,而我们仍然只想要一个输出,那这多个分布要怎么处理才能得到单个输出?
December 10th, 2019
苏神你好~最近在看您的bert4keras源码,layers.py的213行好像有个小错误,self.v_dim应该改成self.output_dim吧?虽然PE的concat模式几乎没人用,您可以看下
谢谢,已修正。这确实是个历史遗留问题。
December 21st, 2019
苏神你好!非常感谢您的分享~
请问这漂亮的模型图示是用什么软件画的呢?
draw.io
谢谢
March 18th, 2020
苏神,想请教一下segment ids的主要作用是什么?
在bert里边是为了在两个句子concat在一起的情况下来区分不同的句子。不过后来roberta的结果也表明,segment_ids其实加不加都无妨。
April 21st, 2020
请问苏神问啥不用pytorch谢,keras很难调试啊
建议不要问这么无聊的问题,这是个人爱好问题而已。如果非要问,那我只能说:谁叫pytorch不早个四五年出来呢?
顺便提醒一句:一直要依赖于动态图才能完成调试的,不管用什么框架,都很难真正成长起来(在写模型方面)。
苏神你好,真不是无聊的问题,最主要还是水平太菜需要用pytorch。没办法行云流水的写模型,而且keras的debug要转写成numpy。不过您这么说提供了指导方向,我也努力试着像您说的方法写。还有一个问题,您是否准备加入xlnet的相关内容和具体用例那?
这就是无聊的问题。你用keras还是pytorch我管不着,至于我爱用哪个也是我自己的事情,你要交流pytorch那就去找有交流pytorch的地方,为啥要问我用不用pytorch?我用不用pytorch都好,都是一件非常自然的事情,你这样的问法,弄得好像我不用pytorch就很不合理那样?
October 9th, 2020
苏神好,想请教您一个问题,如果要把您的这个“篇章 + 问题 → 答案”模型改成“篇章 +答案 → 问题”的模型,需要修改哪些部分呢(新手上路,感谢苏神!)
你要真读懂了本模型,那不用改都行。
多谢苏神回复
1:我说一下我的理解,我想要“篇章 +答案 → 问题”的模型,只要将训练数据改成“篇章 +答案 → 问题”的模式训练出来即可,不知道是否正确
2:还有另一个不太明白的地方:目前答案的生成使用的是抽取式的执行方式(mode设为extractive)如果我想要生成问题,是否应该改成生成式的执行方式,此时的mode应该设为什么值
不好意思,是我看错了,你是在阅读理解这篇文章评论的。你要看问题生成的话,直接看另一篇文章就好了啊:https://kexue.fm/archives/7630
September 21st, 2022
token_ids = p_token_ids + qa_token_ids[1:]
segment_ids = p_segment_ids + qa_segment_ids[1:]
苏神,以上是data_generator里的一段代码,求问为什么加的是qa_token_ids,而不是q_token_ids?a_token_id加上去不是提前曝光信息了吗?
有unilm的mask,看不到后面的信息。