






7
Jun
通用爬虫探索(三):效果展示与代码
By 苏剑林 | 2017-06-07 | 72300位读者 |部分效果 #
部分网站的爬取效果。其中图1是本博客的爬取效果,表明该方案是适用一般网站的;图2和图3是两个开源的论坛程序搭建起来的论坛的爬取效果,表明对于开源程序能够正常爬取;图4是对著名的天涯论坛的爬取效果,表明哪怕是公司内部开发的论坛,也具有不错的效果。

6-blog

6-Discuz
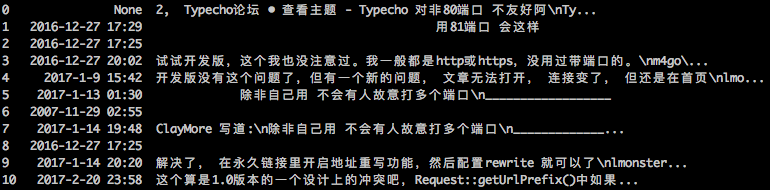
6-phpbb
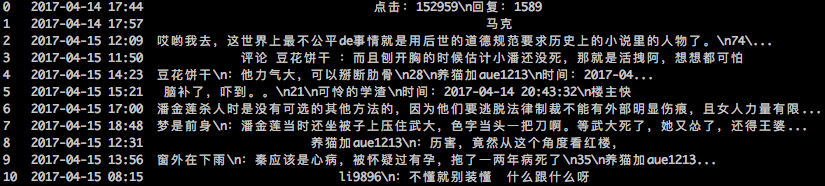
6-tianya
改进空间 #
总的来说,这是一种较高效率的、无监督的通用网站爬取方案,能够自适应不同的网站(不局限于论坛),适合企业大规模部署。
当然,这种方案也有一些有待改进的地方:
1、保证效率和稳定性,牺牲了普适,比如对内容取舍时,直接按照中文占比来判断,没有用到更精确的语言模型方案;
2、进一步的提升空间较小,因为基于标准模板比较的方案,直接混合式地提出了有效文本,丢失了位置和层次信息,虽然通过聚类可以进一步解决这个情况,但还是存在失效的网站,在原来方法基础上的提升空间不大;
3、没有利用到视觉信息,比如没法准确定位用户名,是因为我们不知道那里才算是用户名,但是如果肉眼去看的话,那是比较容易判断的,也就是说,视觉信息是一个比较重要的指标,如果精准度要求更高的话,我们需要利用视觉信息。
期待看到更好的解决方案。
代码 #
Python2.7代码~
通用爬取框架:
#! -*- coding:utf-8 -*-
import requests as rq
import numpy as np
import re
from lxml.html import html5parser
class crawler:
def __init__(self, standard_urls):
self.title = ''
self.emphase_mark = set(['p', 'br', 'em', 'strong', 'b', 'font', 'u', 'a', 'img', 'h1', 'h2', 'h3', 'h4', 'h5', 'sup', 'sub', 'blockquote', 'cite', 'code', 'pre'])
self.standard_urls = standard_urls
self.sess = rq.Session()
self.standard_contents = []
self.find_title = re.compile('<title>([\s\S]*?)</title>').findall
if isinstance(standard_urls, list):
self.standard_dom = self.create_dom(self.standard_urls[0])
self.standard_contents = set([c[1:] for c in self.traverse_dom(self.standard_dom)[1]])
for url in self.standard_urls[1:]:
self.standard_dom = self.create_dom(url)
self.standard_contents = self.standard_contents & set([c[1:] for c in self.traverse_dom(self.standard_dom)[1]])
else:
self.standard_dom = self.create_dom(self.standard_urls)
self.standard_contents = set([c[1:] for c in self.traverse_dom(self.standard_dom)[1]])
self.find_zh = re.compile(u'[\u4e00-\u9fa5]').findall
self.find_zh_en = re.compile(u'[a-zA-Z\d_\u4e00-\u9fa5]').findall
self.find_date = re.compile(u'.*?年.*?月.*?日|发布时间|\d{4}\-\d{1,2}\-\d{1,2}|昨天|前天|今天|小时前|\d{1,2}:\d{2}').findall
def create_dom(self, url):
r = self.sess.get(url)
return html5parser.fromstring(r.content)
def traverse_dom(self, dom, idx=0, tag=''):
content = []
if len(dom) > 0:
tag += (str(dom.tag)+'_')
if dom.tag not in self.emphase_mark:
idx += 1
idx_ = idx
if dom.text and dom.text.strip():
content.append((idx_, tag, dom.text.strip()))
for d in dom:
idx, content_ = self.traverse_dom(d, idx, tag)
content.extend(content_)
if dom.tail and dom.tail.strip():
content.append((idx_, tag, dom.tail.strip()))
elif dom.tag != 'head':
if dom.text and dom.text.strip():
content.append((idx, tag, dom.text.strip()))
if dom.tail and dom.tail.strip():
content.append((idx, tag, dom.tail.strip()))
if (isinstance(dom.tag, str) or isinstance(dom.tag, unicode)) and 'title' in dom.tag and not self.title:
self.title = dom.text.strip() + dom.tail.strip()
return idx, content
def peak(self, d):
r = []
if d[0] > d[1]:
r.append(0)
for i in range(1, len(d)-1):
if d[i] > max(d[i-1], d[i+1]):
r.append(i)
if len(d) >= 3 and d[-1] > d[-2]:
r.append(len(d)-1)
return r
def keep_proba(self, s):
if len(self.find_zh_en(s)) == len(s):
return 1
else:
c0 = len(''.join(self.find_date(s)))
return 1.*(len(self.find_zh(s))+c0)/(len(s))
def crawl_url(self, url, cluster_times=2):
self.title = ''
dom = self.create_dom(url)
content = self.traverse_dom(dom)[1]
content_ = []
for c in content:
if c[1:] not in self.standard_contents:
content_.append(list(c))
content = [content_[0]]
for c in content_:
if c[0] == content[-1][0]:
content[-1] = [c[0], c[1], content[-1][2]+'\n'+c[2]]
else:
content.append(c)
content = [c for c in content if self.keep_proba(c[2]) >= 0.25]
for _ in range(cluster_times):
content_ = content[:]
if len(content_) >= 3:
idxs = [c[0] for c in content_]
idxs = set([idxs[i+1] for i in self.peak(np.diff(idxs))])
content = [content_[0]]
cc = 1
for i in range(1, len(content_)):
if content_[i][0] in idxs:
content[-1][0] = int(content[-1][0]/cc)
content.append(content_[i])
cc = 1
else:
content[-1] = [content[-1][0]+content_[i][0], content[-1][1], content[-1][2]+'\n'+content_[i][2]]
cc += 1
return [c[2] for c in content]
落实到论坛:
def find_datetime(s):
r = []
for t in s.split('\n'):
l = len(t)*1.
d = re.findall('\d+\-\d+\-\d+ +\d+:\d+', t)
if d and len(d[0])/l > 0.5:
r.append(d[0])
else:
d = re.findall(u'\d+年 *\d+月 *\d+日 +\d+:\d+', t)
if d and len(d[0])/l > 0.5:
d = re.findall(u'(\d+)年 *(\d+)月 *(\d+)日 +(\d+):(\d+)', t)
r.append('%s-%s-%s %s:%s'%d[0])
else:
r.append(None)
return r
def extract_info(b,c):
r = []
for t in b:
dts = find_datetime(t)
t = t.split('\n')
dt = max(dts)
if dt:
idx = dts.index(dt)
r.append((dt, '\n'.join(t[:idx]), '\n'.join(t[idx+1:])))
else:
r.append((None, '\n'.join(t), '\n'.join(t)))
idx = 1 + (sum([c.keep_proba(i[1]) for i in r]) < sum([c.keep_proba(i[2]) for i in r]))
r = [(i[0], i[idx]) for i in r if i[idx]]
if not r[0][0]:
r = r[1:]
rr = [r[0]]
for a,b in r[1:]:
if not a:
rr[-1] = rr[-1][0], rr[-1][1]+'\n'+b
else:
rr.append((a,b))
return rr
if __name__ == '__main__':
c = crawler(['http://bbs.emath.ac.cn/thread-9531-1-1.html', 'http://bbs.emath.ac.cn/thread-2749-1-1.html'])
b = c.crawl_url('http://bbs.emath.ac.cn/thread-9538-1-1.html')
title = c.title
r = extract_info(b,c)
keys = ('publish_date', 'content', 'title', 'author')
final = {}
final['post'] = dict(zip(keys, (r[0][0], r[0][1], title, '')))
final['replys'] = [dict(zip(keys, (i[0], i[1], title, ''))) for i in r[1:]]
import pandas as pd
pd.DataFrame(r)转载到请包括本文地址:https://www.spaces.ac.cn/archives/4430
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Jun. 07, 2017). 《通用爬虫探索(三):效果展示与代码 》[Blog post]. Retrieved from https://www.spaces.ac.cn/archives/4430
@online{kexuefm-4430,
title={通用爬虫探索(三):效果展示与代码},
author={苏剑林},
year={2017},
month={Jun},
url={\url{https://www.spaces.ac.cn/archives/4430}},
}

June 7th, 2017
博主您好:
对于爬虫,我的理解是它从互联网公开的信息搜集特定信息,并且保存到自己的数据库中。
拿爬取网页来说,如果一个人能拿取到一个网页的的所有文件,然后在本地配合一些搜索工具,比如用grep配合正则表达搜索指定的关键字,是不是能达到和爬虫一样的功能?
或者说,爬虫的关键在于,在这个人无法拿取某个网页的所有文件的情况下,通过那个网页的互联网接口去“自动化”下载相关文件,从而达到“拿取到一个网页的所有文件”?
你的理解基本是对的。
第一篇文章说到了,爬虫基本包括两点:下载+提取。两步都有一定的困难。下载自有它的难度,但如果更有效、更快捷甚至更通用地提取,也是有困难的。比如像你说的设计正则表达式,这个针对特定的网站自然没问题,如果你有很多网站要提取,那就要给每个网站设计一个正则表达式了,因为它们基本是不通用的。
July 12th, 2017
解析用css更合适,pyquery用法类似jquery
考虑效率应该用多线程或者异步。用tornado抓也很简单。
用pyspider框架更合适,没必要自造轮子(用了上面两个)
你好,暂时没看懂你说的与本文的联系。
另外,其实我不是自造轮子,而是弄不懂复杂的工具,所以自己写,自认为这样的写法是最简洁明了的(而不是逞英雄故意复杂化)
比你这个轮子简单
你并没有懂作者的意思,针对某个网站进行抓取可以有很多轮子,但是作者做的是通用型的。
谢谢帮助解释
August 7th, 2017
自己以前也写过一些爬虫,但是通用性比较差,基本都是针对具体网站来的,本来想看看你的代码,参考一下,但是一点注释都没有,可读性真的不这么好呀,要想读懂基本设断点,然后跑一遍,看一些函数的作用
我都写了前面两篇文章来介绍了。你只读代码当然可读性不好了。弄懂前面两篇文章,代码跟文章的每个步骤都是一一对应的。
September 14th, 2018
chrome headless + puppeteer + nodejs 这个是爬虫的未来