






15
Apr
GlobalPointer下的“KL散度”应该是怎样的?
By 苏剑林 | 2022-04-15 | 38852位读者 | 引用最近有读者提到想测试一下GlobalPointer与R-Drop结合的效果,但不知道GlobalPointer下的KL散度该怎么算。像R-Drop或者虚拟对抗训练这些正则化手段,里边都需要算概率分布的KL散度,但GlobalPointer的预测结果并非一个概率分布,因此无法直接进行计算。
经过一番尝试,笔者给出了一个可用的形式,并通过简单实验验证了它的可行性,遂在此介绍笔者的分析过程。
对称散度
KL散度是关于两个概率分布的函数,它是不对称的,即$KL(p\Vert q)$通常不等于$KL(q\Vert p)$,在实际应用中,我们通常使用对称化的KL散度:
\begin{equation}D(p,q) = KL(p\Vert q) + KL(q\Vert p)\end{equation}
21
Feb
GPLinker:基于GlobalPointer的事件联合抽取
By 苏剑林 | 2022-02-21 | 111917位读者 | 引用大约两年前,笔者在百度的“2020语言与智能技术竞赛”中首次接触到了事件抽取任务,并在文章《bert4keras在手,baseline我有:百度LIC2020》中分享了一个转化为BERT+CRF做NER的简单baseline。不过,当时的baseline更像是一个用来凑数的半成品,算不上一个完整的事件抽取模型。而这两年来,关系抽取的模型层见迭出,SOTA一个接一个,但事件抽取似乎没有多亮眼的设计。
最近笔者重新尝试了事件抽取任务,在之前的关系抽取模型GPLinker的基础上,结合完全子图搜索,设计一个比较简单但相对完备的事件联合抽取模型,依然称之为GPLinker,在此请大家点评一番。
任务简介
事件抽取是一个比较综合的任务。一个标准的事件抽取样本如下:
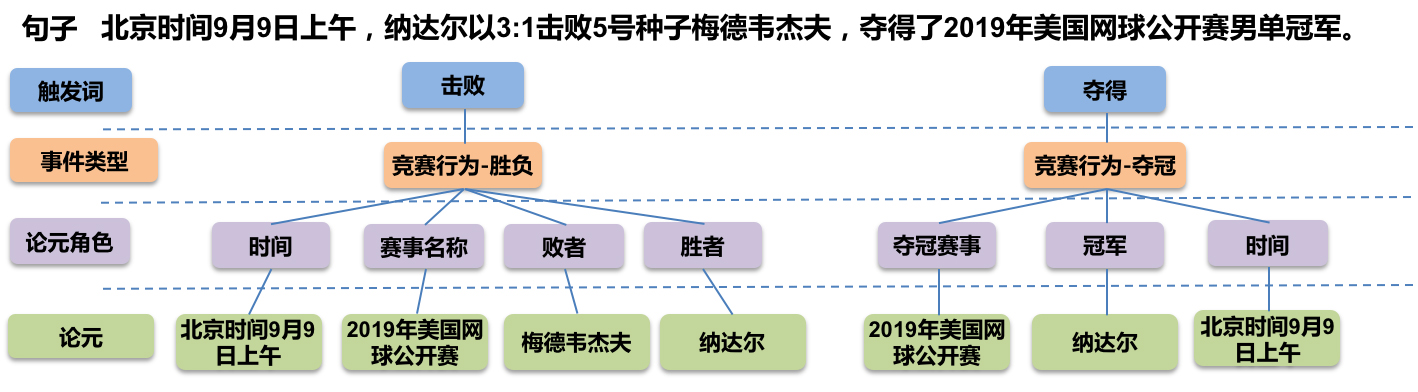
标准的事件抽取样本(图片来自百度DuEE的GitHub)
30
Jan
GPLinker:基于GlobalPointer的实体关系联合抽取
By 苏剑林 | 2022-01-30 | 184308位读者 | 引用在将近三年前的百度“2019语言与智能技术竞赛”(下称LIC2019)中,笔者提出了一个新的关系抽取模型(参考《基于DGCNN和概率图的轻量级信息抽取模型》),后被进一步发表和命名为“CasRel”,算是当时关系抽取的SOTA。然而,CasRel提出时笔者其实也是首次接触该领域,所以现在看来CasRel仍有诸多不完善之处,笔者后面也有想过要进一步完善它,但也没想到特别好的设计。
后来,笔者提出了GlobalPointer以及近日的Efficient GlobalPointer,感觉有足够的“材料”来构建新的关系抽取模型了。于是笔者从概率图思想出发,参考了CasRel之后的一些SOTA设计,最终得到了一版类似TPLinker的模型。
基础思路
关系抽取乍看之下是三元组$(s,p,o)$(即subject, predicate, object)的抽取,但落到具体实现上,它实际是“五元组”$(s_h,s_t,p,o_h,o_t)$的抽取,其中$s_h,s_t$分别是$s$的首、尾位置,而$o_h,o_t$则分别是$o$的首、尾位置。
25
Jan
Efficient GlobalPointer:少点参数,多点效果
By 苏剑林 | 2022-01-25 | 192723位读者 | 引用在《GlobalPointer:用统一的方式处理嵌套和非嵌套NER》中,我们提出了名为“GlobalPointer”的token-pair识别模块,当它用于NER时,能统一处理嵌套和非嵌套任务,并在非嵌套场景有着比CRF更快的速度和不逊色于CRF的效果。换言之,就目前的实验结果来看,至少在NER场景,我们可以放心地将CRF替换为GlobalPointer,而不用担心效果和速度上的损失。
在这篇文章中,我们提出GlobalPointer的一个改进版——Efficient GlobalPointer,它主要针对原GlobalPointer参数利用率不高的问题进行改进,明显降低了GlobalPointer的参数量。更有趣的是,多个任务的实验结果显示,参数量更少的Efficient GlobalPointer反而还取得更好的效果。
大量的参数
这里简单回顾一下GlobalPointer,详细介绍则请读者阅读《GlobalPointer:用统一的方式处理嵌套和非嵌套NER》。简单来说,GlobalPointer是基于内积的token-pair识别模块,它可以用于NER场景,因为对于NER来说我们只需要把每一类实体的“(首, 尾)”这样的token-pair识别出来就行了。
1
May
GlobalPointer:用统一的方式处理嵌套和非嵌套NER
By 苏剑林 | 2021-05-01 | 527092位读者 | 引用(注:本文的相关内容已整理成论文《Global Pointer: Novel Efficient Span-based Approach for Named Entity Recognition》,如需引用可以直接引用英文论文,谢谢。)
本文将介绍一个称为GlobalPointer的设计,它利用全局归一化的思路来进行命名实体识别(NER),可以无差别地识别嵌套实体和非嵌套实体,在非嵌套(Flat NER)的情形下它能取得媲美CRF的效果,而在嵌套(Nested NER)情形它也有不错的效果。还有,在理论上,GlobalPointer的设计思想就比CRF更合理;而在实践上,它训练的时候不需要像CRF那样递归计算分母,预测的时候也不需要动态规划,是完全并行的,理想情况下时间复杂度是$\mathcal{O}(1)$!
简单来说,就是更漂亮、更快速、更强大!真有那么好的设计吗?不妨继续看看。
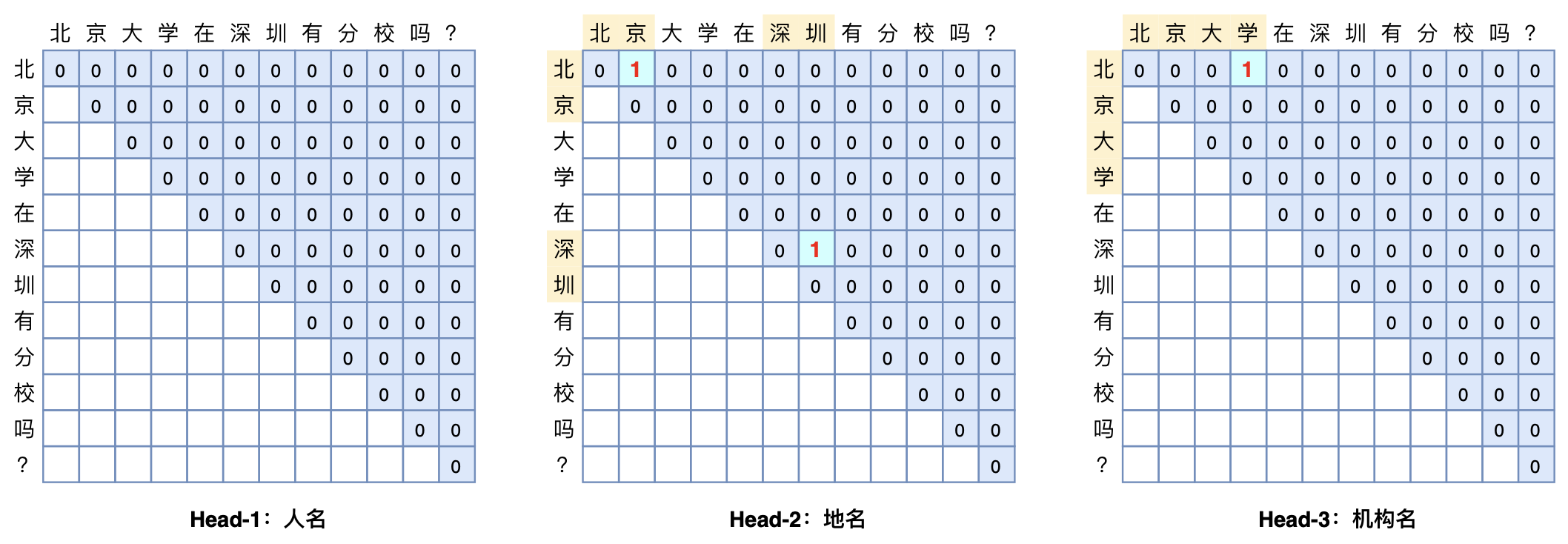
GlobalPointer多头识别嵌套实体示意图
3
Sep
百度实体链接比赛后记:行为建模和实体链接
By 苏剑林 | 2019-09-03 | 114863位读者 | 引用前几个月曾参加了百度的实体链接比赛,这是CCKS2019的评测任务之一,官方称之为“实体链指”,比赛于前几个星期完全结束。笔者最终的F1是0.78左右(冠军是0.80),排在第14名,成绩并不突出(唯一的特色是模型很轻量级,GTX1060都可以轻松跑起来),所以本文只是纯粹的记录过程,大牛们请一笑置之~
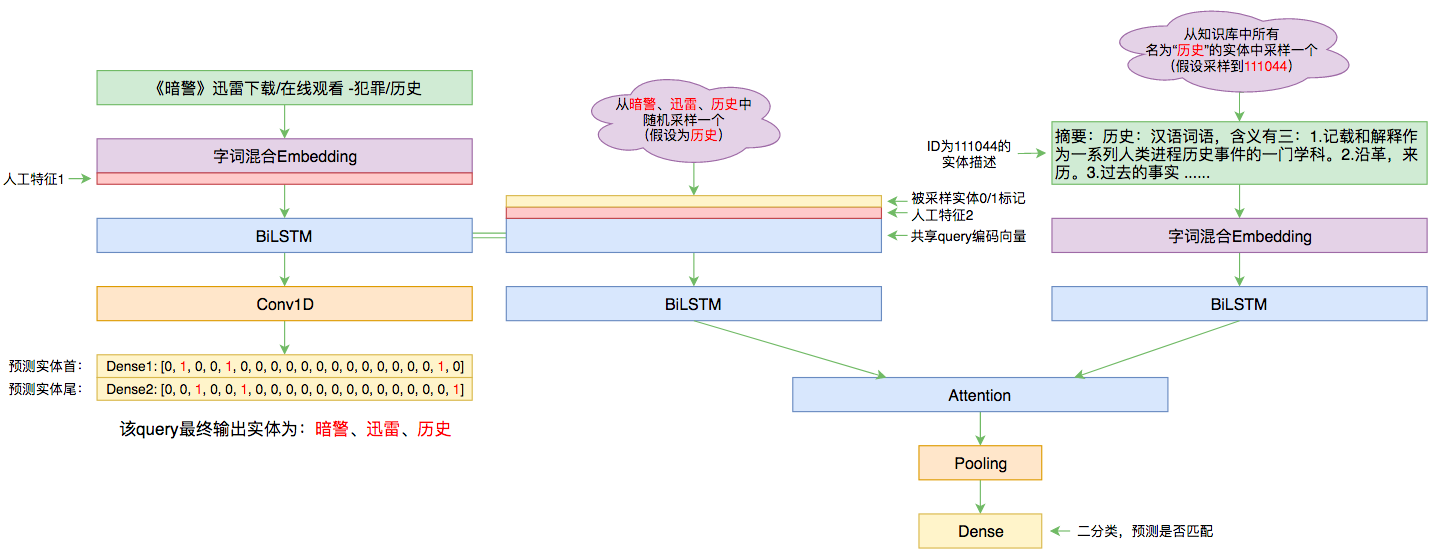
本文的实体链接模型总图(可以点击查看大图)
赛题介绍
所谓实体链接,主要指的是在已有一个知识库的情况下,预测输入query的某个实体对应知识库id。也就是说,知识库里边记录了很多实体,对于同一个名字的实体可能会有多个解释,每个解释用一个唯一id编号,我们要做的就是预测query中的实体究竟对应哪一个解释(id)。这是基于知识图谱的问答系统的必要步骤。
6
Sep
基于双向LSTM和迁移学习的seq2seq核心实体识别
By 苏剑林 | 2016-09-06 | 207485位读者 | 引用暑假期间做了一下百度和西安交大联合举办的核心实体识别竞赛,最终的结果还不错,遂记录一下。模型的效果不是最好的,但是胜在“端到端”,迁移性强,估计对大家会有一定的参考价值。
比赛的主题是“核心实体识别”,其实有两个任务:核心识别 + 实体识别。这两个任务虽然有关联,但在传统自然语言处理程序中,一般是将它们分开处理的,而这次需要将两个任务联合在一起。如果只看“核心识别”,那就是传统的关键词抽取任务了,不同的是,传统的纯粹基于统计的思路(如TF-IDF抽取)是行不通的,因为单句中的核心实体可能就只出现一次,这时候统计估计是不可靠的,最好能够从语义的角度来理解。我一开始就是从“核心识别”入手,使用的方法类似QA系统:
1、将句子分词,然后用Word2Vec训练词向量;
2、用卷积神经网络(在这种抽取式问题上,CNN效果往往比RNN要好)卷积一下,得到一个与词向量维度一样的输出;
3、损失函数就是输出向量跟训练样本的核心词向量的cos值。

最近评论