






25
May
Google新作Synthesizer:我们还不够了解自注意力
By 苏剑林 | 2020-05-25 | 142195位读者 |深度学习这个箱子,远比我们想象的要黑。
写在开头 #
据说物理学家费曼说过一句话[来源]:“谁要是说他懂得量子力学,那他就是真的不懂量子力学。”我现在越来越觉得,这句话中的“量子力学”也可以替换为“深度学习”。尽管深度学习已经在越来越多的领域证明了其有效性,但我们对它的解释性依然相当无力。当然,这几年来已经有不少工作致力于打开深度学习这个黑箱,但是很无奈,这些工作基本都是“马后炮”式的,也就是在已有的实验结果基础上提出一些勉强能说服自己的解释,无法做到自上而下的构建和理解模型的原理,更不用说提出一些前瞻性的预测。
本文关注的是自注意力机制。直观上来看,自注意力机制算是解释性比较强的模型之一了,它通过自己与自己的Attention来自动捕捉了token与token之间的关联,事实上在《Attention is All You Need》那篇论文中,就给出了如下的看上去挺合理的可视化效果:
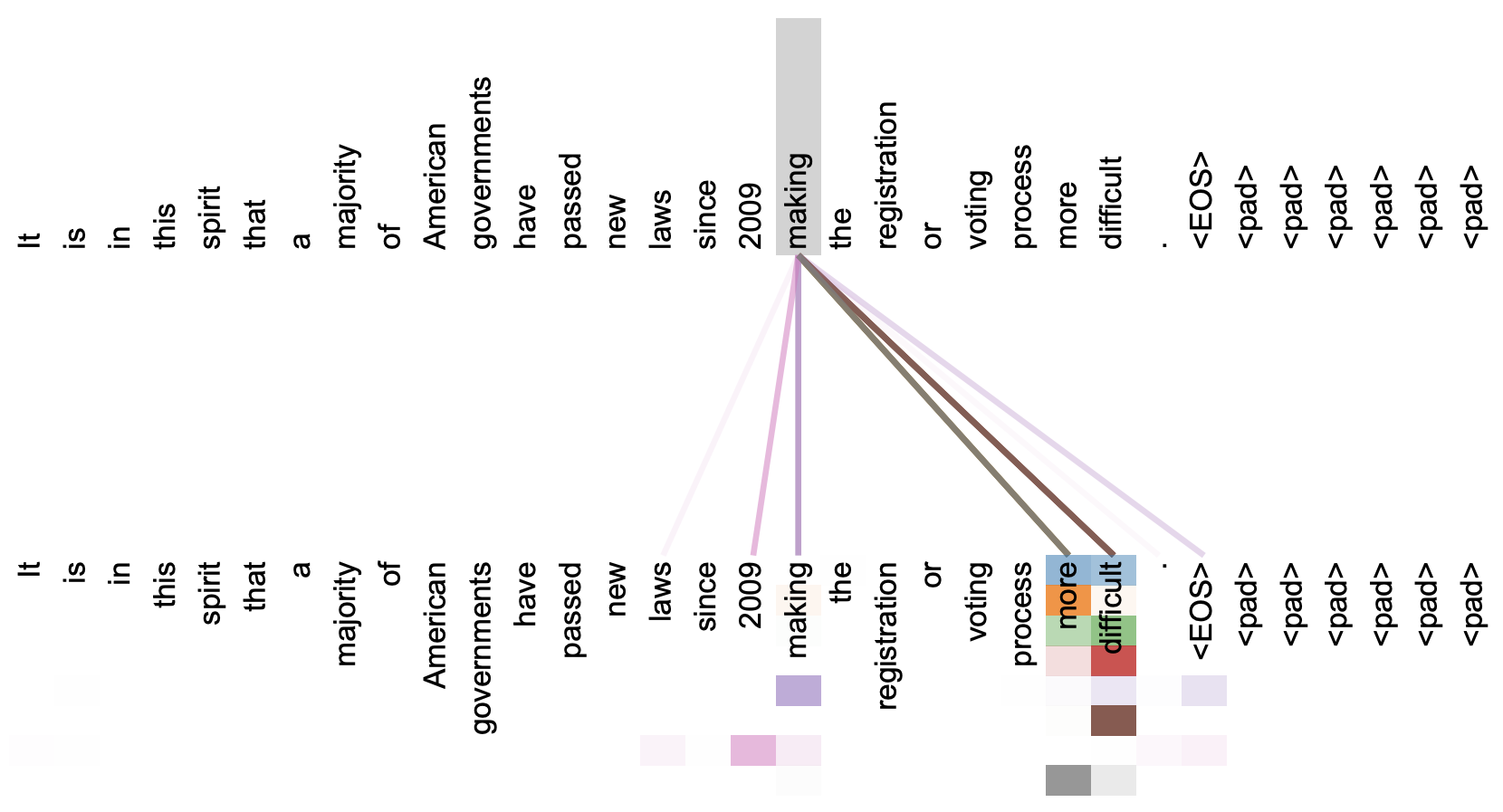
《Attention is All You Need》一文中对Attention的可视化例子
但自注意力机制真的是这样生效的吗?这种“token对token”的注意力是必须的吗?前不久Google的新论文《Synthesizer: Rethinking Self-Attention in Transformer Models》对自注意力机制做了一些“异想天开”的探索,里边的结果也许会颠覆我们对自注意力的认知。
自注意力 #
自注意力模型的流行,始于2017年Google发表的《Attention is All You Need》一文,关于它的科普读者还可以参考笔者旧作《Attention is All You Need》浅读(简介+代码)。它的基础是Scaled-Dot Attention,定义如下:
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\frac{\boldsymbol{Q}\boldsymbol{K}^{\top}}{\sqrt{d_k}}\right)\boldsymbol{V}\end{equation}
其中$\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}, \boldsymbol{K}\in\mathbb{R}^{m\times d_k}, \boldsymbol{V}\in\mathbb{R}^{m\times d_v}$,softmax则是在$m$的那一维进行归一化。而自注意力,则是对于同一个$\boldsymbol{X}\in \mathbb{R}^{n\times d}$,通过不同的投影矩阵$\boldsymbol{W}_q,\boldsymbol{W}_k,\boldsymbol{W}_v\in\mathbb{R}^{d\times d'}$得到$\boldsymbol{Q}=\boldsymbol{X}\boldsymbol{W}_q,\boldsymbol{K}=\boldsymbol{X}\boldsymbol{W}_k,\boldsymbol{V}=\boldsymbol{X}\boldsymbol{W}_v$,然后再做Attention,即
\begin{equation}\begin{aligned}
SelfAttention(\boldsymbol{X}) =&\, Attention(\boldsymbol{X}\boldsymbol{W}_q, \boldsymbol{X}\boldsymbol{W}_k, \boldsymbol{X}\boldsymbol{W}_v)\\
=&\, softmax\left(\frac{\boldsymbol{X}\boldsymbol{W}_q \boldsymbol{W}_k^{\top}\boldsymbol{X}^{\top}}{\sqrt{d_k}}\right)\boldsymbol{X}\boldsymbol{W}_v&
\end{aligned}\end{equation}
至于Multi-Head Attention,则不过是Attention运算在不同的参数下重复多次然后将多个输出拼接起来,属于比较朴素的增强。而关于它的进一步推广,则可以参考《突破瓶颈,打造更强大的Transformer》。
天马行空 #
本质上来看,自注意力就是通过一个$n\times n$的矩阵$\boldsymbol{A}$和$d\times d'$的矩阵$\boldsymbol{W}_v$,将原本是$n\times d$的矩阵$\boldsymbol{X}$,变成了$n\times d'$的矩阵$\boldsymbol{A}\boldsymbol{X}\boldsymbol{W}_v$。其中矩阵$\boldsymbol{A}$是动态生成的,即
\begin{equation}\boldsymbol{A}=softmax\left(\boldsymbol{B}\right),\quad\boldsymbol{B}=\frac{\boldsymbol{X}\boldsymbol{W}_q \boldsymbol{W}_k^{\top}\boldsymbol{X}^{\top}}{\sqrt{d_k}}\end{equation}
对于矩阵$\boldsymbol{B}$,本质上来说它就是$\boldsymbol{X}$里边两两向量的内积组合,所以我们称它为“token对token”的Attention。
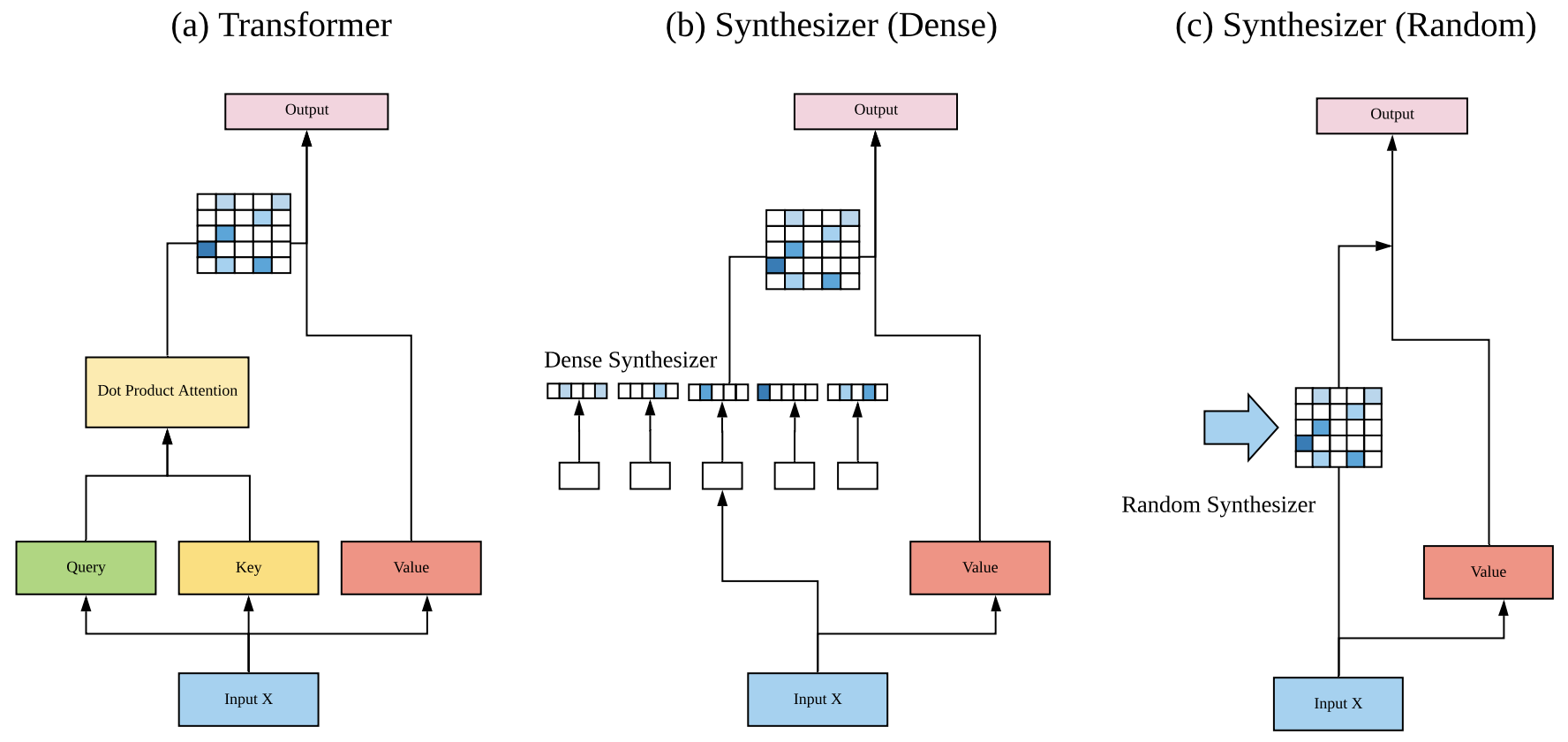
Synthesizer自注意力与标准自注意力的对比
那么,就到了前面提出的问题:“token对token”是必须的吗?能不能通过其他方式来生成这个矩阵$\boldsymbol{B}$?Google的这篇论文正是“天马行空”了几种新的形式并做了实验,这些形式统称为Synthesizer。
Dense形式 #
第一种形式在原论文中称为Dense:$\boldsymbol{B}$需要是$n\times n$大小的,而$\boldsymbol{X}$是$n\times d$的,所以只需要一个$d\times n$的变换矩阵$\boldsymbol{W}_a$就可以将它变成$n\times n$了,即
\begin{equation}\boldsymbol{B}=\boldsymbol{X}\boldsymbol{W}_a\end{equation}
这其实就相当于把$\boldsymbol{K}$固定为常数矩阵$\boldsymbol{W}_a^{\top}$了。当然,原论文还做得更复杂一些,用到了两层Dense层:
\begin{equation}\boldsymbol{B}=\text{relu}\left(\boldsymbol{X}\boldsymbol{W}_1 + \boldsymbol{b}_1\right)\boldsymbol{W}_2 + \boldsymbol{b}_2\end{equation}
但思想上并没有什么变化。
Random形式 #
刚才说Dense形式相当于把$\boldsymbol{K}$固定为常数矩阵,我们还能不能更“异想天开”一些:把$\boldsymbol{Q}$固定为常数矩阵?这时候整个$\boldsymbol{B}$相当于是一个常数矩阵,即
\begin{equation}\boldsymbol{B}=\boldsymbol{R}\end{equation}
原论文中还真是实验了这种形式,称之为Random,顾名思义,就是$\boldsymbol{B}$是随机初始化的,然后可以选择随训练更新或不更新。据原论文描述,固定形式的Attention首次出现在论文《Fixed Encoder Self-Attention Patterns in Transformer-Based Machine Translation》,不同点是那里的Attention矩阵是由一个函数算出来的,而Google这篇论文则是完全随机初始化的。从形式上看,Random实际上就相当于可分离卷积(Depthwise Separable Convolution)运算。
低秩分解 #
上面两种新形式,往往会面对着参数过多的问题,所以很自然地就想到通过低秩分解来降低参数量。对于Dense和Random,原论文也提出并验证了对应的低秩分解形式,分别称为Factorized Dense和Factorized Random。
Factorized Dense通过Dense的方式,生成两个$n\times a, n\times b$的矩阵$\boldsymbol{B}_1,\boldsymbol{B}_2$,其中$ab=n$;然后将$\boldsymbol{B}_1$重复$b$次、然后将$\boldsymbol{B}_2$重复$a$次,得到对应的$n\times n$矩阵$\tilde{\boldsymbol{B}}_1,\tilde{\boldsymbol{B}}_2$,最后将它们逐位相乘(个人感觉相乘之前$\tilde{\boldsymbol{B}}_2$应该要转置一下比较合理,但原论文并没有提及),合成一个$n\times n$的矩阵:
\begin{equation}\boldsymbol{B}=\tilde{\boldsymbol{B}}_1 \otimes \tilde{\boldsymbol{B}}_2\end{equation}
至于Factorized Random就很好理解了,本来是一整个$n\times n$的矩阵$\boldsymbol{R}$,现在变成两个$n\times k$的矩阵$\boldsymbol{R}_1,\boldsymbol{R}_2$,然后
\begin{equation}\boldsymbol{B}=\boldsymbol{R}_1\boldsymbol{R}_2^{\top} \end{equation}
混合模式 #
到目前为止,连同标准的自注意力,我们有5种不同的生成矩阵$\boldsymbol{B}$的方案,它们也可以混合起来,即
\begin{equation}\boldsymbol{B}=\sum_{i=1}^N \alpha_i \boldsymbol{B}_i\end{equation}
其中$\boldsymbol{B}_i$是不同形式的自注意力矩阵,而$\sum\limits_{i=1}^N \alpha_i=1$是可学习参数。
结果分析 #
前面介绍了统称为Synthesizer的几种新型自注意力形式,它们的共同特点是没有保持“token对token”形式,尤其是Random,则完全抛弃了原有注意力的动态特点,变成了静态的矩阵。
那么,这些新型自注意力的效果如何呢?它们又怎样冲击我们对自注意力机制的认识呢?
机器翻译 #
第一个评测任务是机器翻译,详细地比较了各种自注意力形式的效果:
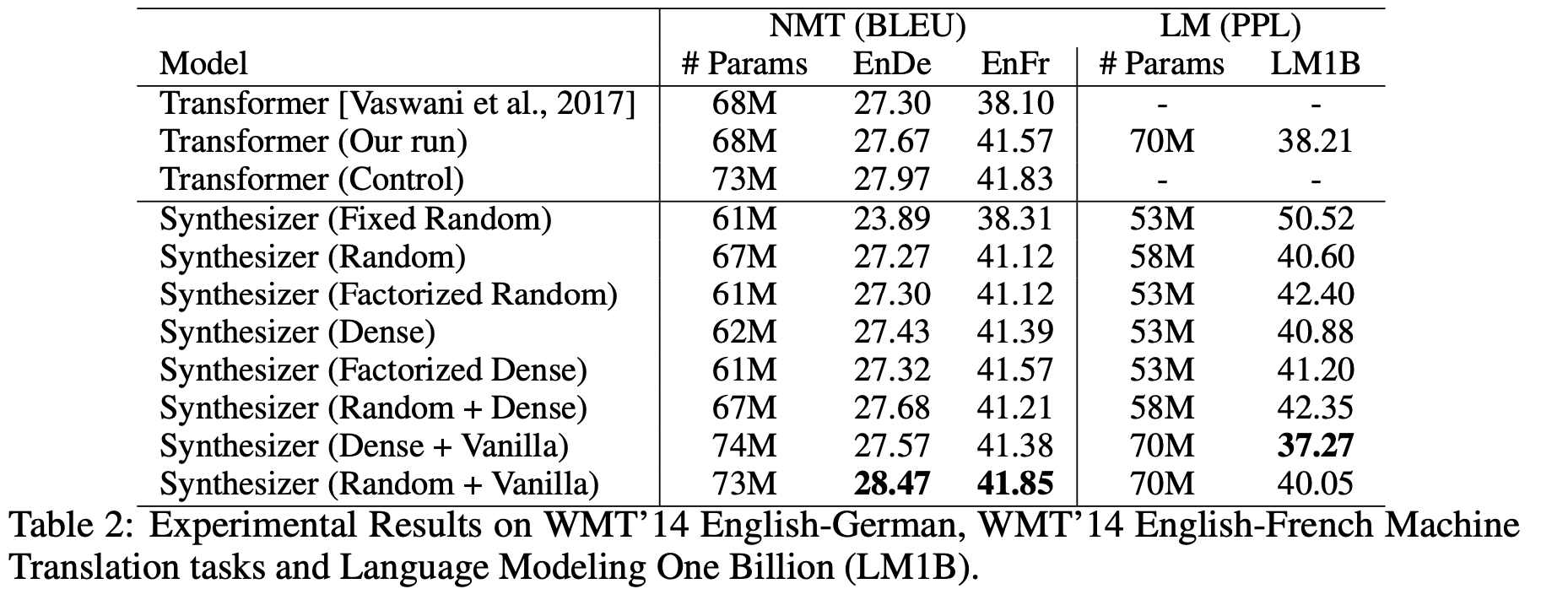
Synthesizer在机器翻译任务上的表现对比
不知道读者怎么想,反正Synthesizer的这些结果是冲击了笔者对自注意力的认知的。表格显示,除了固定的Random外,所有的自注意力形式表现基本上都差不多,而且就算是固定的Random也有看得过去的效果,这表明我们以往对自注意力的认知和解释都太过片面了,并没有揭示自注意力生效的真正原因。
摘要对话 #
接下来在摘要和对话生成任务上的结果:

Synthesizer在摘要和对话任务上的表现对比
在自动摘要这个任务上,标准注意力效果比较好,但是对话生成这个任务上,结果则反过来:标准的自注意力是最差的,Dense(D)和Random(R)是最好的,而当Dense和Random混合了标准的自注意力后(即 D+V 和 R+V),效果也变差了。这说明标准注意力并没有什么“独占鳌头”的优势,而几个Synthesizer看起来是标准注意力的“退化”,但事实上它们互不从属,各有优势。
预训练+微调 #
最后,对于我们这些普通读者来说,可能比较关心是“预训练+微调”的效果怎样,也就是说,将BERT之类的模型的自注意力替换之后表现如何?原论文确实也做了这个实验,不过Baseline不是BERT而是T5,结果如下:
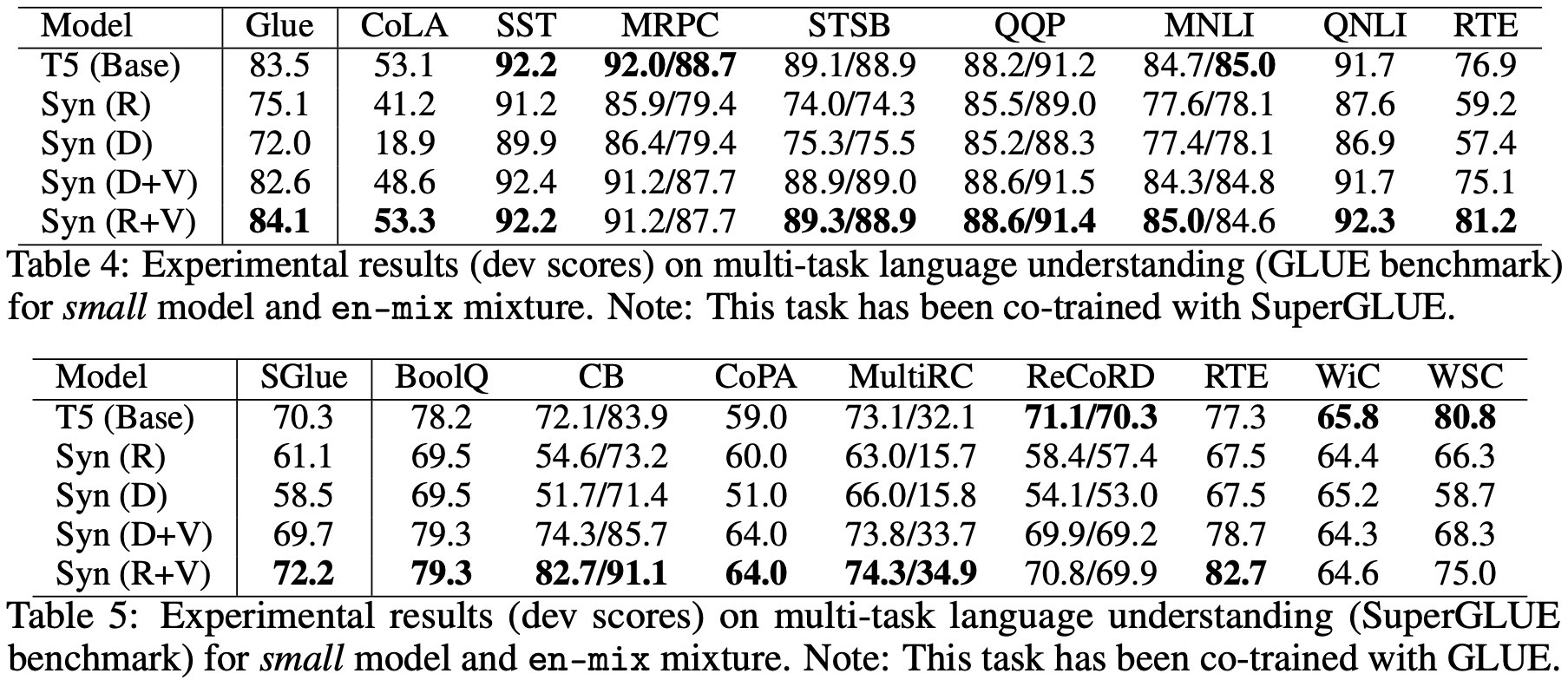
Synthesizer在“预训练+微调”的表现对比
在这个结果中,相比标准自注意力,Dense和Random就显得逊色了,这表明Dense和Random也许会在单一任务上表现得比较好,而迁移能力则比较弱。但是不能否定的是,像Random这样的自注意力,由于直接省去了$\boldsymbol{Q}\boldsymbol{K}^{\top}$这个矩阵运算,因此计算效率会有明显提升,因此如果能想法子解决这个迁移性问题,说不准Transformer模型家族将会迎来大换血。
文末小结 #
本文介绍了Google的新工作Synthesizer,它是对目前流行的自注意力机制的反思和探索。论文中提出了几种新型的自注意力机制,并做了相当充分的实验,而实验结果很可能会冲击我们对自注意力机制的已有认知,值得大家读读~
转载到请包括本文地址:https://www.spaces.ac.cn/archives/7430
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (May. 25, 2020). 《Google新作Synthesizer:我们还不够了解自注意力 》[Blog post]. Retrieved from https://www.spaces.ac.cn/archives/7430
@online{kexuefm-7430,
title={Google新作Synthesizer:我们还不够了解自注意力},
author={苏剑林},
year={2020},
month={May},
url={\url{https://www.spaces.ac.cn/archives/7430}},
}

July 11th, 2022
苏神,式(9)的$\alpha$是随机初始化还是由函数计算出来的?式(9)可以看成矩阵$B$的基矩阵的线性组合吗?
随即初始化。
August 18th, 2022
苏神,synthesizer的random形式的attention,是否可以理解成一种bias呢?类似于一个linear层的bias,只不过变成了矩阵的形式。
为什么不是kernel而是bias?
April 13th, 2023
苏神,synthesizer的random形式的attention引入了n*n的矩阵,但是N是一个不确定的值,怎么来事现初始化呢
synthesizer应该事先固定了最大的$n$。
October 20th, 2023
注意力矩陣如果由幾個稀疏矩陣相乘而得到,既可降低時間複雜度又可滿秩。
一般的稀疏矩阵乘法并不是那么容易降低复杂度的~
January 21st, 2024
這些替代方案的問題是,沒辦法像原始的 attention 一樣把 weight 可視化出來。很多 attention 的應用不只是看任務的準確度,而是要利用 attention weight 取出有用的資訊。比方說我可以用bert finetune 下游任務後,取出 attention weight 來找出對下游任務最重要的關鍵字,這就可以當成是一種自動摘要或可解釋性的方案。
當 attention 取出來的東西跟我們認知差異太大時,可以判斷該結果可能有問題,就算答案是對的,但推論過程不一定是對的。例如他可能attention到某個符號,而這符號只會出現在某個來源的文章,剛好該來源大部分都是某類文章,結果就錯誤歸因了,而非真的從語意中學到該分類。這或許可以解釋上面結果為何遷移能力較弱,因為 synthesizer 可能只學習到資料中某些表面的訊號,並沒有深層理解字義。要深層理解字義,必然要給出字跟意義之間的正確歸因,然而現實世界的資料雜訊太多,錯誤歸因的情況難以避免,更高的準確率有可能只是擬合到了錯誤的歸因。然而 attention 是一個鼓勵正確歸因的模型,因為錯置的 attention weight 不容易泛化到不同樣本,只有正確歸因的 attention weight 能容易泛化到其它樣本。
因此我認為,從可解釋性的角度, attention 相較於上面的 synthesizer 或其它種方法,還是一個比較容易理解的模型。
應該說,attention的token對token機制,鼓勵了正確歸因。因為 query中的某個token,可以歸因到key中的某個token。但在上面的 synthesizer 方法中,省略了q, k 的對應,等於只用一個q來計算attention,這樣就有可能造成錯誤歸因。想像q裡面一個token,他只靠自己產生attention,跟與k交互產生attention,若k不同於q時(例如cross attention),就有機會消除掉錯誤歸因。因為q中的同一個token,可能對應到不同k的某個token,這樣就消除了只依賴於q自己所可能產生的錯誤歸因。
而在bert的情況下,兩個句子用sep分開,所以其實不用cross attention,只要看句子1的q對句子2的k所產生的attention,再加上next sentence prediction,把句子2換成另外一個句子,然後讓模型辨識出差異,這樣就構成了一個q對應到兩個不同k,這時候q中所學到的特徵就必需不能是虛假關聯,否則他就無法正確分辨兩者的差異。因此就消除了虛假關聯,從而提升了泛化能力。
我認為泛化能力,也可理解為消除虛假關聯的能力。比方說某個字經常同某個字一起出現,但他們兩個可能根本沒甚麼關係,但是在統計上,某批資料中這兩個字共同出現的機率就很高,行長虛假關聯。然而泛化要求的是這兩個字如果各別出現在別的領域的資料中,能夠按照他原來的意義被理解。而在別的領域中,你就不能得到這兩個字會經常一起出現的統計現象了。這時,next sentence prediction 的作用就有點像模擬來自兩個不同domain的資料的情況,起到了消除某些虛假關聯的作用。
因此我認為 BERT的 next sentence prediction可能是它可以容易微調泛化到不同領域的重要關鍵。
怎么说呢,从现在的LLM角度来看,追求模型内部的可解释性几乎毫无意义,一切都只是scale up(model size、data size)
不过确实,我以前发现,Linear Attention训练出来的BERT,在微调迁移时效果远远不如标准Attention的BERT(但预训练的效果相当),所以说明架构本身应该会影响迁移能力,甚至Pre Norm/Post Norm的区别也会明显微调效果。但又回到LLM时代,微调已经基本不重要了,大家都在追求直接能用的通用AI(当然,在这个目标完全实现之前,微调还有一定的用武之地),所以过于纠结模型架构上的事情意义不大了。
謝謝你的回答!其實我目前在讀博士班,我的研究方向並不追求使用LLM的直接應用(那大部分已經屬於工程上的技巧,無法用來發paper),反倒是要嘗試一些NLP目前還未解決的問題,例如可解釋性、可遷移性...等。所以不能說有了LLM其他都不重要了,不然我們做NLP的都不要做研究了...
我能理解学术上的需要,但上面我主要想说的是,其实模型对人类来说的一些可解释性,可能无法代表模型真正在拟合数据时的能力,最经典之一就是注意力机制,人们想象它应该像注意力那样描述了token与token之间的相对重要性,并且也以“注意力”命名,但实际训练出来的Attention矩阵是很难解释的(或者说至少从人类的角度是很难理解)。
另一方面,神经网络本身是高度过参数化的。大致意思是说,假设一个任务理论上可以用x参数量就能完成,但实际要scale到10x参数量的实际效果才比较好,多出来的9x参数量实际上比较冗余,但又不得不加(这可能跟梯度下降有关),而加了之后可能就会把原本能解释的部分给掩盖了。
不過還是有一些可視化的應用,最經典的例如影像上的熱力圖,有些人嘗試把 stable diffution 中 cross attention weight 拿出來,發現輸入的文字可以直觀的對應到圖上的部份,例如輸入"帽子",attention weight 就會特別關注到影像上的帽子部分。
我認為你說的人類難以理解,是因為模型是從 low level 開始訓練的,自然很難得到甚麼有意義的解釋。token跟token之間本來就難以理解。但是文字跟影像之間就存在 high level 的關係,因為人是看圖的整塊區域,不是看像素,而文字的意義是一個詞或一個句子來理解的,不是看一個token。所以我們可以從生成的圖像跟輸入的文字中找到某種高層的對應關係,而非一個像素對一個token的關係。
回到文字上,token對token 這種方式,可能無法反映出人類可理解的意義。真要說,應該是句子對句子比較有意義。只是目前的建模方式,也不用斷句了,透過模型的強大能力,直接從token level 開始,層數深一點,就能夠表示句子;而生成的方式,是一個token一個token生成的,並非像人類一樣,是先有概念,由概念構成句子,再輸出成文字。人類可理解的,是屬於概念的層次,而非文字之間怎麼組成。我們不用懂中文語法也能講中文,因為大腦的底層已經幫我們做了這件事了,所以我們在想事情時,是以概念來進行思考的,而非一個字一個字思考,這跟目前的模型有很大的差別。
因此我認為,如果是以句子或子句為單位來建模,它的可解釋性會比較清楚。至於底下詞跟詞之間怎麼關聯的,無法解釋也沒有關係。就像在量子尺度很多事情無法用常理解釋,但是當這些效應加總起來,到了巨觀尺度時,就又變得可解釋了。你不必懂量子力學,也能用可解釋的方式算出行星軌道,就是這個道理。
所以我認為可解釋性是存在的,只是目前建模的層次不是人類可理解的層次。就好像模型給你的是量子之間的關係,然而你能理解的是巨觀的現象,中間存在一個gap,但是語言又不像物理,可以有一些理論來銜接巨觀與量子尺度,所以造成了人類很難理解模型到底在做甚麼。而我們的任務應該是找到人類可理解的層次,讓模型在這個層次上輸出可解釋的訊號。
1、不是人类可理解的解释性还叫可解释吗?(我不知道);
2、如果句子足够多,那么是不是也没有“比较清楚”的可解释性了?
3、视觉上的Attention确实能做一些归因的事情,但相比于直接分析Attention矩阵,类似“积分梯度( https://kexue.fm/archives/7533 )”之类的模型无关的方法其实更加主流,也可以用到NLP中。
1. 我的意思是,人類可理解的範圍是有限的,聚焦在高階的概念。但是模型是從低階開始建模的,如 bit-level 或 token-level,低階的運作方式可能完全不同於高階的方式,追求低階的可解釋性可能本來就是沒有意義的。就像你一開始提到費曼說的:「如果有人說他懂量子力學,那他就是不懂。」,因為量子力學是作用在原子以下的尺度,其運作方式完全不同於巨觀物理。因此追求理解量子力學可能是沒有意義的。但是由量子力學集體產生的巨觀現象,卻是人類可以理解的。我想強調的是"尺度"的問題。
模型并不是一个字一个字思考,而是每次只讲出来一个字。
模型内部也未必一个字一个字地思考,它只是一个字一个字地读。