






8
Sep
有限内存下全局打乱几百G文件(Python)
By 苏剑林 | 2021-09-08 | 105389位读者 |这篇文章我们来做一道编程题:
如何在有限内存下全局随机打乱(Shuffle)几百G的文本文件?
题目背景其实很明朗,现在预训练模型动辄就几十甚至几百G语料了,为了让模型能更好地进行预训练,对训练语料进行一次全局的随机打乱是很有必要的。但对于很多人来说,几百G的语料往往比内存还要大,所以如何能在有限内存下做到全局的随机打乱,便是一个很值得研究的问题了。
已有工具 #
假设我们的文件是按行存储的,也就是一行代表一个样本,我们要做的就是按行随机打乱文件。假设我们只有一个文件,并且这个文件大小明显小于内存,那么我们可以用linux自带的shuf命令:
shuf input.txt -o output.txt之所以强调文件大小明显小于内存,是因为shuf会把整个文件加载到内存中再打乱的,这就要求我们有足够大的内存。针对此,一个改进版叫terashuf(链接),它通过切分文件的方式,用硬盘空间代替内存,使得我们可以打乱大于内存的文件。
看上去terashuf已经完全能满足我们的需求了。理论上确实是的,但是有时候我们可能会有很多个性化的需求,比如将多个文件混合起来随机打乱,或者将打乱后的输出切分为多个文件,等等。因此,我们最好能够自己用Python把它实现出来,以便应对更复杂的定制需求。
打乱算法 #
现在我们来看一下,在有限内存下进行全局打算的算法究竟是怎样的呢?大体上步骤如下:
1、假设文件共有$mn$行,那么分割为$m$个文件,每个文件$n$行;
2、每个$n$行的文件内部随机打乱,因为这个$n$是任意指定的,因此这步可以在内存中完成;
3、读取每个文件的第一行(得到$m$行数据),将这$m$行数据随机写入到输出文件中;
4、依次读取每个文件的第$2,\cdots,n$行,重复第3步操作。
说白了,就是先竖着打乱一遍,然后横着打乱一遍,就能得到一个充分打乱的结果,接近全局打乱,如下图:
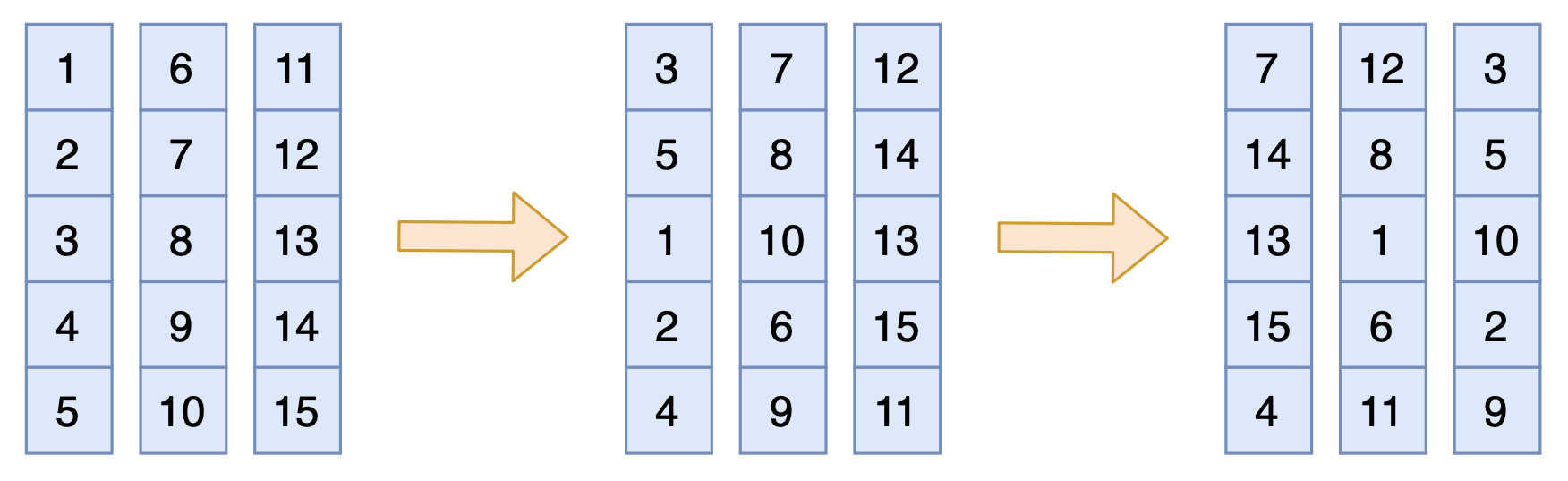
左:原始数据;中:每列内部纵向打乱;右:在纵向打乱的基础上,每行横向打乱
注意这样的算法只能保证得到一个尽可能乱的结果,但是无法保证任何排序都有可能出现,比如输出的前2个样本不可能正好是第1个文件的前2个样本。如果要真正实现所有排序等概率出现,需要我们每一步都按照每个文件的剩余行数来依概率采样,而不是同时读完每个文件的第$k$行再读每个文件的第$k+1$行。但每一步都依概率采样会增加采样成本,而且对于实际使用来说效果也差别不大,因此没太大必要。
实际情况下,按每个文件$n$行来分割文件时,最后一个文件可能不足$n$行,如果我们不在乎这个小细节,那么依旧可以按照上述流程执行,而最后一个文件先被读取完后,继续返回空行就好,整个流程不会报错。当然,这会导致最后一个文件的样本排序偏前,对于有强迫症的读者可能无法接受这一点,这时可以考虑在读取最后一个文件的时候,引入拒绝采样,拒绝率为$1-\frac{\text{最后一个文本剩余行数}}{\text{其余每个文本剩余行数}}$。
参考实现(没有引入拒绝采样):
性能测试 #
如果只是合并、打乱、分割三种操作的结合,那么其实用shell命令加terashuf也可以实现,大致命令为
cat corpus/*.json | TMPDIR=/root/tmp MEMORY=20 ./terashuf | split -l 100000 -a 5 -d - corpus-经比较,在同样的环境下,总大小约为280G的文件,用terashuf进行打乱的总时间大致为2.7小时,而笔者所写的Python代码运行时间大约为3.5小时。看起来Python代码也不是慢很多,还能接受,毕竟terashuf是C++写的,Python比C++慢并不丢人。
大多数情况下,这个全局打乱算法的瓶颈是磁盘IO速度,因此多进程/多线程基本上都不是特别管用。
本文小结 #
本文简单介绍了一下在有限内存下借助硬盘空间进行大文件全局打乱的思路,并给出了一个Python实现,有需要的读者可以自行派生出更复杂需求的代码。
转载到请包括本文地址:https://www.spaces.ac.cn/archives/8662
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Sep. 08, 2021). 《有限内存下全局打乱几百G文件(Python) 》[Blog post]. Retrieved from https://www.spaces.ac.cn/archives/8662
@online{kexuefm-8662,
title={有限内存下全局打乱几百G文件(Python)},
author={苏剑林},
year={2021},
month={Sep},
url={\url{https://www.spaces.ac.cn/archives/8662}},
}

September 8th, 2021
有点大数据那个味道了,,,两层递归打乱,,,第一步hash分桶,第二部桶内打乱
不是递归,,,就是基于分治,,
是的。原始的想法是给每个文件建索引,然后打乱索引,但是发现,就算是建立了索引,把样本取出来的速度也太慢了...
直接第一步,,,建立一个均匀hash,,m个文件,就除以m取余,,,然后这个过程:可以递归,可以嵌套,也可以分布式(交换幺半)(因为这m文件互不影响),,,所以,其实是一个依赖外部存储的K路归并排序的逆过程,,
September 8th, 2021
其实这得看对“全局打乱”的定义。
如果只要求“ 每条样本出现在每个位置的概率是相等的”的话,一个更简单的做法是:shuffle(x) = [x[k:], x[:k]] 其中 k 在 0, len(x)) 中 uniform sample。
如果要求“所有排列有相同的概率”的话,文中的做法不一定满足该定义。
很显然本文的做法是满足该定义的。
该算法相当于从 (m!)^n * (n!)^m 个(带重复的)排列中 uniform sample 出一个。令 m = n = 4,该数字不是 5 的倍数,故不可能是 (mn)! 的倍数,故不是所有排列被 sample 到的概率都相同。
你的排列公式我暂时没想懂,不过我想了想,确实并非所有排列都有可能出现,比如输出的前2个样本不可能正好是第1个文件的前2个样本。
只能说这个算法的结果提供了一种尽可能充分打乱的输出,而不是所有排列都等概率,但直觉来想,这个算法的输出空间正好是所有可能的排列之中比较“乱”的部分?
如果要严格使得每种排列可能性一样,应该要每一步都依概率采样才行。我已经修改了本文的部分表达。
再次感谢指出~
哦这个公式的意思是:一个 m 行 n 列的矩阵,打乱一行的方案数是 n!,打乱一列的方案数是 m! ,所以打乱一次所有行再打乱一次所有列的总方案数是 (m!)^n * (n!)^m. 从古典概型的角度来思考,最终每个排列出现的概率的分母都是这个数。
不过实际应用中我觉得这个算法完全能满足需求,只不过不能 claim 它有一个完美的理论依据。我们应该能找到一个不错的理论依据,例如排列的分布和 uniform 分布之间的某个 distance 不大之类的,但是这个就得仔仔细细地算了……
感谢指导
September 9th, 2021
假如底层磁盘文件系统支持的话,可以把每一行放到单独的block中,不同block之间用指针链接。那么后续的所有操作,只要改变这个指针就可以了。也就是说,重复相同数据的读出写入是没必要的。所以一开始那个280GB的文件本身,就设计的不甚合理,哪怕换成sqlite数据库,后续使用都方便的多。。
September 9th, 2021
要分成m个文件,直接先打开m个空白文件句柄不关闭,然后每行读取大文件,并产生一个m以内的随机数,把该行添加到第m个文件,最后都关闭句柄即可。
也是个思路,这样可以使得分割更为随机。但实际情况下,我们一般是指定每个文件的行数,而不确定总的文件数(当然可以实现做个估计)。
September 10th, 2021
为啥不用mmap,一遍遍历完事
mmap没改变本质吧,也不能提高效率。
可以多进程啊
瓶颈是IO,多进程也没用~