






3
Apr
P-tuning:自动构建模版,释放语言模型潜能
By 苏剑林 | 2021-04-03 | 235732位读者 |在之前的文章《必须要GPT3吗?不,BERT的MLM模型也能小样本学习》中,我们介绍了一种名为Pattern-Exploiting Training(PET)的方法,它通过人工构建的模版与BERT的MLM模型结合,能够起到非常好的零样本、小样本乃至半监督学习效果,而且该思路比较优雅漂亮,因为它将预训练任务和下游任务统一起来了。然而,人工构建这样的模版有时候也是比较困难的,而且不同的模版效果差别也很大,如果能够通过少量样本来自动构建模版,也是非常有价值的。
最近Arxiv上的论文《GPT Understands, Too》提出了名为P-tuning的方法,成功地实现了模版的自动构建。不仅如此,借助P-tuning,GPT在SuperGLUE上的成绩首次超过了同等级别的BERT模型,这颠覆了一直以来“GPT不擅长NLU”的结论,也是该论文命名的缘由。
什么是模版 #
所谓PET,主要的思想是借助由自然语言构成的模版(英文常称Pattern或Prompt),将下游任务也转化为一个完形填空任务,这样就可以用BERT的MLM模型来进行预测了。比如下图中通过条件前缀来实现情感分类和主题分类的例子:

通过特定模版将情感分类转换为MLM任务
通过特定模版将新闻分类转换为MLM任务
当然,这种方案也不是只有MLM模型可行,用GPT这样的单向语言模型(LM)其实也很简单:
通过特定模版将情感分类转换为LM任务
通过特定模版将新闻分类转换为LM任务
不过由于语言模型是从左往右解码的,因此预测部分只能放在句末了(但还可以往补充前缀说明,只不过预测部分放在最后)。
某种意义上来说,这些模版属于语言模型的“探针”,我们可以通过模版来抽取语言模型的特定知识,从而做到不错的零样本效果,而配合少量标注样本,可以进一步提升效果,这些在《必须要GPT3吗?不,BERT的MLM模型也能小样本学习》中已经比较详细讨论过了。
然而,前面已经说了,对于某些任务而言,人工构建模版并不是那么容易的事情,模型的优劣我们也不好把握,而不同模型之间的效果差别可能很大,在这种情况下,人工标注一些样本可能比构建模版还要轻松得多。所以,如何根据已有的标注样本来自动构建模版,便成了一个值得研究的问题了。
P-tuning #
P-tuning重新审视了关于模版的定义,放弃了“模版由自然语言构成”这一常规要求,从而将模版的构建转化为连续参数优化问题,虽然简单,但却有效。
模版的反思 #
首先,我们来想一下“什么是模版”。直观来看,模版就是由自然语言构成的前缀/后缀,通过这些模版我们使得下游任务跟预训练任务一致,这样才能更加充分地利用原始预训练模型,起到更好的零样本、小样本学习效果。
等等,我们真的在乎模版是不是“自然语言”构成的吗?
并不是。本质上来说,我们并不关心模版长什么样,我们只需要知道模版由哪些token组成,该插入到哪里,插入后能不能完成我们的下游任务,输出的候选空间是什么。模版是不是自然语言组成的,对我们根本没影响,“自然语言”的要求,只是为了更好地实现“一致性”,但不是必须的。于是,P-tuning考虑了如下形式的模版:
![P-tuning直接使用[unused*]的token来构建模版,不关心模版的自然语言性](/usr/uploads/2021/04/2868831073.png)
P-tuning直接使用[unused*]的token来构建模版,不关心模版的自然语言性
这里的[u1]~[u6],代表BERT词表里边的[unused1]~[unused6],也就是用几个从未见过的token来构成模板,这里的token数目是一个超参数,放在前面还是后面也可以调整。接着,为了让“模版”发挥作用,我们用标注数据来求出这个模板。
如何去优化 #
这时候,根据标注数据量的多少,我们又分两种情况讨论。
第一种,标注数据比较少。这种情况下,我们固定整个模型的权重,只优化[unused1]~[unused6]这几个token的Embedding,换句话说,其实我们就是要学6个新的Embedding,使得它起到了模版的作用。这样一来,因为模型权重几乎都被固定住了,训练起来很快,而且因为要学习的参数很少,因此哪怕标注样本很少,也能把模版学出来,不容易过拟合。
第二种,标注数据很充足。这时候如果还按照第一种的方案来,就会出现欠拟合的情况,因为只有6个token的可优化参数实在是太少了。因此,我们可以放开所有权重微调,原论文在SuperGLUE上的实验就是这样做的。读者可能会想:这样跟直接加个全连接微调有什么区别?原论文的结果是这样做效果更好,可能还是因为跟预训练任务更一致了吧。
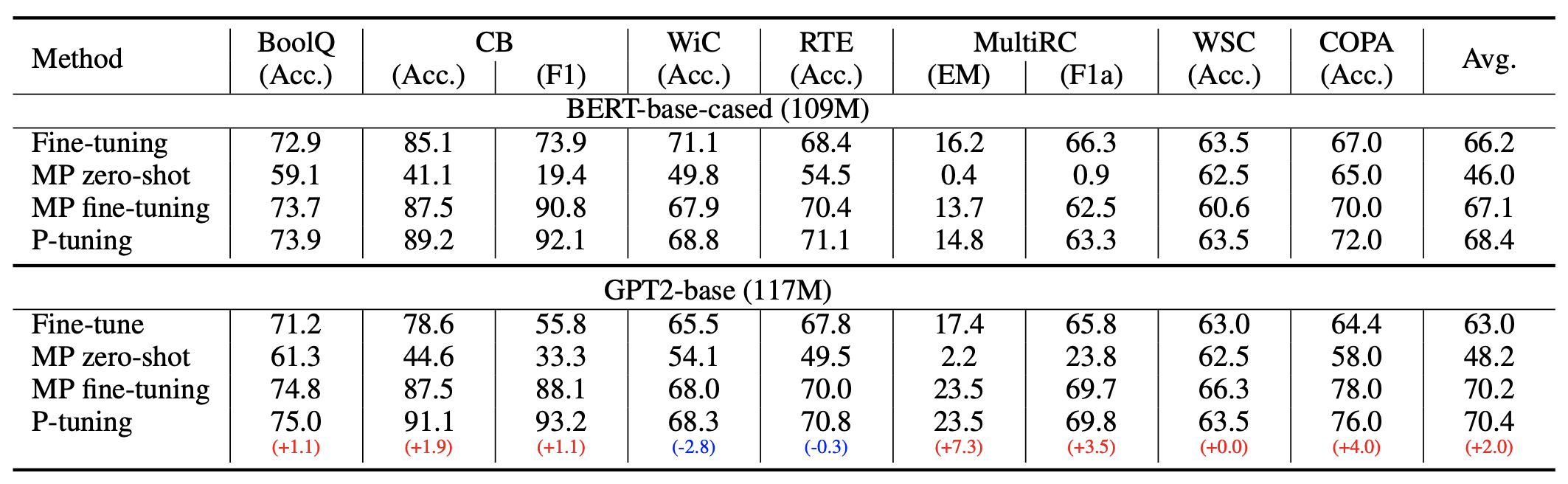
P-tuning在SuperGLUE上的表现
此外,在上面的例子中,目标token如“很”、“体育”是人为选定的,那么它们可不可以也用[unused*]的token代替呢?答案是可以,但也分两种情况考虑:1、在标注数据比较少的时候,人工来选定适当的目标token效果往往更好些;2、在标注数据很充足的情况下,目标token用[unused*]效果更好些,因为这时候模型的优化空间更大一些。
增强相关性 #
在原论文中,P-tuning并不是随机初始化几个新token然后直接训练的,而是通过一个小型的LSTM模型把这几个Embedding算出来,并且将这个LSTM模型设为可学习的。这样多绕了一步有什么好处呢?原论文大概的意思是:LSTM出现的token表示相关性更强,某种程度上来说更像“自然语言”(因为自然语言的token之间不是独立的),此外还能防止局部最优。我在Github上进一步向作者确认了一下(参考这里),效果上的差别是通过LSTM多绕一步的方法可以使得模型收敛更快、效果更优。
然而,这样多了一个LSTM,总感觉有些别扭,而且实现上也略微有点麻烦。按照作者的意思,LSTM是为了帮助模版的几个token(某种程度上)更贴近自然语言,但这并不一定要用LSTM生成,而且就算用LSTM生成也不一定达到这一点。笔者认为,更自然的方法是在训练下游任务的时候,不仅仅预测下游任务的目标token(前面例子中的“很”、“新闻”),还应该同时做其他token的预测。
比如,如果是MLM模型,那么也随机mask掉其他的一些token来预测;如果是LM模型,则预测完整的序列,而不单单是目标词。这样做的理由是:因为我们的MLM/LM都是经过自然语言预训练的,所以我们(迷之自信地)认为能够很好完成重构的序列必然也是接近于自然语言的,因此这样增加训练目标,也能起到让模型更贴近自然语言的效果。经过笔者的测试,加上这样辅助目标,相比单纯优化下游任务的目标,确实提升了效果。
实验与效果 #
所谓“talk is cheap, show me the code”,又到了喜闻乐见的实验时间了。这里分享一下P-tuning的实验结果,其中还包括笔者对P-tuning的实现思路,以及笔者在中文任务上的实验结果。
停止的梯度 #
怎么实现上述的P-tuning算法比较好呢?如果是放开所有权重训练,那自然是简单的,跟普通的BERT微调没有什么区别。关键是在小样本场景下,如何实现“只优化几个token”呢?
当然,实现的方法也不少,比如为那几个要优化的token重新构建一个Embedding层,然后拼接到BERT的Embedding层中,然后训练的时候只放开新Embedding层的权重。但这样写对原来模型的改动还是蛮大的,最好的方法是尽可能少改动代码,让使用者几乎无感。为此,笔者构思了一种用stop_gradient简单修改Embedding层的方案,大体上是将Embedding层修改如下:
class PtuningEmbedding(Embedding):
"""新定义Embedding层,只优化部分Token
"""
def call(self, inputs, mode='embedding'):
embeddings = self.embeddings
embeddings_sg = K.stop_gradient(embeddings)
mask = np.zeros((K.int_shape(embeddings)[0], 1))
mask[1:9] += 1 # 只优化id为1~8的token
self.embeddings = embeddings * mask + embeddings_sg * (1 - mask)
return super(PtuningEmbedding, self).call(inputs, mode)
变量经过stop_gradient算子后,在反向传播的时候梯度为0,但是前向传播不变,因此在上述代码中,前向传播的结果不会有变化,但是反向传播求梯度的时候,梯度不为0的token由mask变量控制,其余token的梯度都为零,因此就实现了只更新部分token。
完整代码可见:
对了,原论文也开源了代码:
测试与效果 #
前面已经分享了原作者在SuperGLUE上的实验结果,显示出如果配合P-tuning,那么:1、GPT、BERT的效果相比直接finetune都有所提升;2、GPT的效果还能超过了BERT。这表明GPT不仅有NLG的能力,也有NLU能力,可谓是把GPT的潜能充分“压榨”出来了,当然BERT配合P-tuning也有提升,说明P-tuning对语言模型潜能的释放是较为通用的。
原论文的实验比较丰富,建议读者仔细阅读原论文,相信会收获颇多。特别指出的是原论文的Table 2最后一列,当预训练模型足够大的时候,我们的设备可能无法finetune整个模型,而P-tuning可以选择只优化几个Token的参数,因为优化所需要的显存和算力都会大大减少,所以P-tuning实则上给了我们一种在有限算力下调用大型预训练模型的思路。
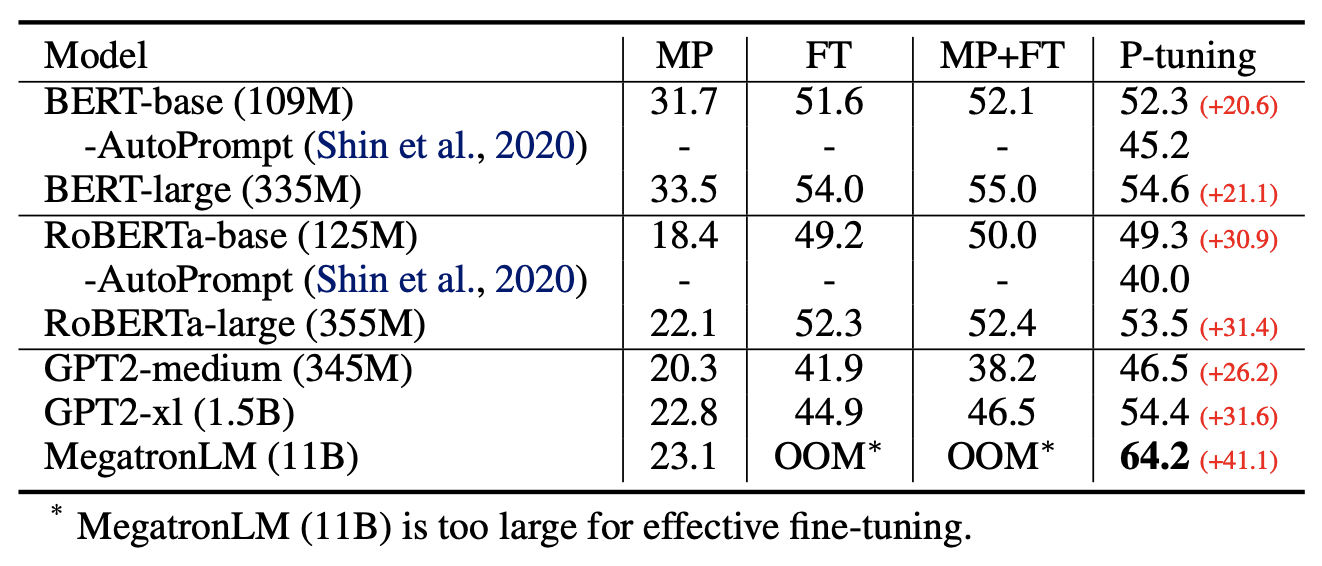
P-tuning在各个体量的语言模型下的效果
当然,笔者一直以来的观点是“没有在中文上测试过的算法是没有灵魂的”,因此笔者也在中文任务上简单测试了,测试任务跟《必须要GPT3吗?不,BERT的MLM模型也能小样本学习》一致,都是情感分类的小样本学习,测试模型包括BERT和GPT,两者的候选模版分别如下图:
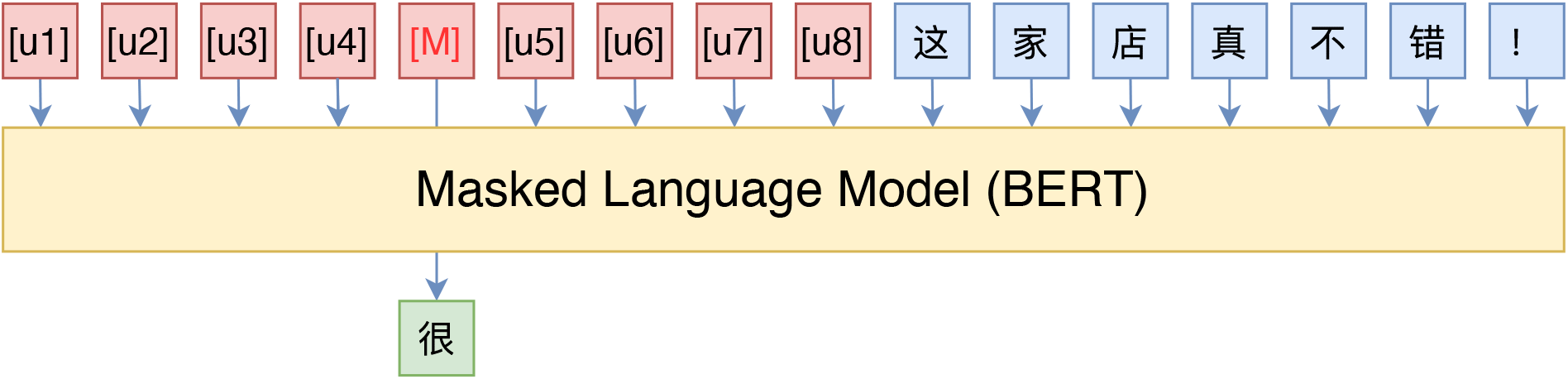
笔者在中文情感分类上使用的“BERT+P-tuning”模版

笔者在中文情感分类上使用的“GPT+P-tuning”模版
注意,对于LM模型,前缀的引入非常重要,只引入后缀时效果会明显变差;而对于MLM模型,前缀的效果通常也优于后缀。总的效果如下表:
$$\begin{array}{c|cc}
\hline
& \text{验证集} & \text{测试集} \\
\hline
\text{小样本直接微调} & 88.93\% & 89.34\% \\
\text{VAT半监督学习} & 89.83\% & 90.37\% \\
\hline
\text{PET零样本} & 85.17\% & 84.27\% \\
\text{PET无监督} & 88.05\% & 87.53\% \\
\text{PET小样本} & 89.29\% & 89.18\% \\
\text{PET半监督} & 90.09\% & 89.76\% \\
\hline
\text{BERT + P-tuning} & 89.81\% & 89.75\% \\
\text{GPT + P-tuning} & 89.30\% & 88.51\% \\
\hline
\end{array}$$
其中“小样本”只用到了“少量标注样本”,“无监督”则用到了“大量无标注样本”,“半监督”则用到了“少量标注样本+大量无标注样本”,“P-tuning”都是小样本,PET的几个任务报告的是最优的人工模版的结果,其实还有更差的人工模版。从小样本角度来看,P-tuning确实取得了最优的小样本学习效果;从模版构建的角度来看,P-tuning确实也比人工构建的模版要好得多;从模型角度看,P-tuning确实可以将GPT的分类性能发挥到跟BERT相近,从而揭示了GPT也有很强的NLU能力的事实。
进一步理解 #
这一节将会介绍笔者对P-tuning的进一步思考,以求从多个维度来理解P-tuning。
离散 vs 连续 #
在P-tuning之前,也已经有一些在做模版的自动构建,如《How Can We Know What Language Models Know?》、《AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts》等,但它们搜索的都是在离散空间下搜索的自然语言模版,所以效果有所限制,并没有取得特别突出的结果。
相反,P-tuning放弃了“模版由自然语言构成”这一要求,从而将其变成了可以简单梯度下降求解的连续参数问题,效果还更好。同时,这一改动意味着P-tuning突出了模版的本质——即模版的关键在于它是怎么用的,不在于它由什么构成——给人一种去芜存菁、眼前一亮额的感觉,确实值得点赞。
(注:经读者@brotherb提醒,年初有一篇论文《Prefix-Tuning: Optimizing Continuous Prompts for Generation》提出的Prefix-Tuning方法其实已经相当接近P-tuning,两者都设计了非自然语言的模版,只不过Prefix-Tuning主要关心NLG的应用而P-tuning更加关心NLU的应用。)
Adapter #
我们还可以从Adapter的角度来理解P-tuning。BERT出来后不久,Google在论文《Parameter-Efficient Transfer Learning for NLP》中提出了一种名为Adapter的微调方式,它并不是直接微调整个模型,而是固定住BERT原始权重,然后在BERT的基础上添加一些残差模块,只优化这些残差模块,由于残差模块的参数更少,因此微调成本更低。Adapter的思路实际上来源于CV的《Learning multiple visual domains with residual adapters》,不过这两年似乎很少看到了,也许是因为它虽然提高了训练速度,但是预测速度却降低了,精度往往还有所损失。
在P-tuning中,如果我们不将新插入的token视为“模版”,是将它视为模型的一部分,那么实际上P-tuning也是一种类似Adapter的做法,同样是固定原模型的权重,然后插入一些新的可优化参数,同样是只优化这些新参数,只不过这时候新参数插入的是Embedding层。因此,从这个角度看,P-tuning与Adapter有颇多异曲同工之处。
为什么有效 #
然后,还有一个值得思考的问题:为什么P-tuning会更好?比如全量数据下,大家都是放开所有权重,P-tuning的方法依然比直接finetune要好,为啥呢?
事实上,提出这个问题的读者,应该是对BERT加个全连接层的直接finetune做法“习以为常”了。很明显,不管是PET还是P-tuning,它们其实都更接近预训练任务,而加个全连接层的做法,其实还没那么接近预训练任务,所以某种程度上来说,P-tuning有效更加“显然”,反而是加个全连接层微调为什么会有效才是值得疑问的。
去年有篇论文《A Mathematical Exploration of Why Language Models Help Solve Downstream Tasks》试图回答这个问题,大致的论证顺序是:
1、预训练模型是某种语言模型任务;
2、下游任务可以表示为该种语言模型的某个特殊情形;
3、当输出空间有限的时候,它又近似于加一个全连接层;
4、所以加一个全连接层微调是有效的。
可以看到,该论文的假设主要是第2点,其实就是直接假设了下游任务可以表达为类似PET的形式,然后才去证明的。所以这进一步说明了,PET、P-tuning等才是更自然的使用预训练模型的方式,加全连接直接finetune的做法其实只是它们的推论罢了,也就是说,PET、P-tuning才是返璞归真、回归本质的方案,所以它们更有效。
简单的总结 #
本文介绍了P-tuning,它是一种模版的自动构建方法,而通过模版我们可以从语言模型中抽取知识,完成零样本、小样本等学习任务,并且效果往往还更好。借助P-tuning,GPT也能实现优秀的NLU效果,在SuperGLUE上的表现甚至超过了BERT。除此之外,P-tuning还一种在有限算力下调用大型预训练模型的有效方案。
转载到请包括本文地址:https://www.spaces.ac.cn/archives/8295
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Apr. 03, 2021). 《P-tuning:自动构建模版,释放语言模型潜能 》[Blog post]. Retrieved from https://www.spaces.ac.cn/archives/8295
@online{kexuefm-8295,
title={P-tuning:自动构建模版,释放语言模型潜能},
author={苏剑林},
year={2021},
month={Apr},
url={\url{https://www.spaces.ac.cn/archives/8295}},
}

October 25th, 2022
[...]P-tuning:自动构建模版,释放语言模型潜能[...]
October 30th, 2022
[...]转载自《必须要GPT3吗?不,BERT的MLM模型也能小样本学习》和《P-tuning:自动构建模版,释放语言模型潜能》,作者:苏剑林,部分内容有修改。[...]
November 20th, 2022
[...]无独有偶,近期在学习苏神的博客的过程中,也看到了类似的结论,具体内容可参考《P-tuning:自动构建模版,释放语言模型潜能》。[...]
April 10th, 2023
苏神,chinese_nezha_gpt_L-12_H-768_A-12这个文件在哪可以下载?
https://github.com/bojone/nezha
https://github.com/bojone/nezha_gpt_dialog
中文情感测试bert任务,把pos_id和neg_id的embedding也放入可优化调整的参数中,训练集Accuracy提升了1PP,而测试集无显著变化,在高维空间中,让pos_id和neg_id的向量距离最大化会不会对测试效果有提升?
这个我没法断言,只能通过实验来回答。
May 30th, 2023
你好,如何优化那一小节第二种方法:标注数据充足只优化6个token,这里是不是说容易过拟合而不是欠拟合?
噢,这里想表达的意思是不足以记下全部训练集的标签。
刚开始看时也一维是过拟合,但是实际上是欠拟合的,因为优化的模型参数不够时,不能更好的拟合标注数据的,所以应该还是欠拟合的。
July 20th, 2023
你好,想请教一下,如果说全量数据的情况下只微调embedding的少量参数容易欠拟合,那么如何解释论文《The Power of Scale for Parameter-Efficient Prompt Tuning》中随着模型参数量的上升,只微调embedding的少量参数的效果会逐渐接近全参数finetune的效果呢?
我只报告我自己的实验结果呀,无法解释所有的论文,毕竟每个方法的设置都不一样。
November 1st, 2023
哈喽,看了你的代码实现,请教个问题:输入层“模版token”的位置是前面4个,后面4个,这样配置的原因是什么?如果都放在前面/后面,效果有差异吗?
没有对比过,只是直觉上认为前后都加比较科学~