






16
Apr
搜狐文本匹配:基于条件LayerNorm的多任务baseline
By 苏剑林 | 2021-04-16 | 129727位读者 |前段时间看到了“2021搜狐校园文本匹配算法大赛”,觉得赛题颇有意思,便尝试了一下,不过由于比赛本身只是面向在校学生,所以笔者是不能作为正式参赛人员参赛的,因此把自己的做法开源出来,作为比赛baseline供大家参考。
赛题介绍 #
顾名思义,比赛的任务是文本匹配,即判断两个文本是否相似,本来是比较常规的任务,但有意思的是它分了多个子任务。具体来说,它分A、B两大类,A类匹配标准宽松一些,B类匹配标准严格一些,然后每个大类下又分为“短短匹配”、“短长匹配”、“长长匹配”3个小类,因此,虽然任务类型相同,但严格来看它是六个不同的子任务。
# A类样本示例
{
"source": "英国伦敦,20/21赛季英超第20轮,托特纳姆热刺VS利物浦。热刺本赛季18轮联赛是9胜6平3负,目前积33分排名联赛第5位。利物浦本赛季19轮联赛是9胜7平3负,目前积34分排名联赛第4位。从目前的走势来看,本场比赛从热刺的角度来讲,是非常被动的。最终,本场比赛的比分为托特纳姆热刺1-3利",
"target": " 北京时间1月29日凌晨4时,英超联赛第20轮迎来一场强强对话,热刺坐镇主场迎战利物浦。 热刺vs利物浦,比赛看点如下: 第一:热刺能否成功复仇?双方首回合,热刺客场1-2被利物浦绝杀,赛后穆里尼奥称最好的球队输了,本轮热刺主场迎战利物浦,借着红军5轮不胜的低迷状态,能否成功复仇? 第二:利物浦近",
"labelA": "1"
}
# B类样本示例
{
"source": "英国伦敦,20/21赛季英超第20轮,托特纳姆热刺VS利物浦。热刺本赛季18轮联赛是9胜6平3负,目前积33分排名联赛第5位。利物浦本赛季19轮联赛是9胜7平3负,目前积34分排名联赛第4位。从目前的走势来看,本场比赛从热刺的角度来讲,是非常被动的。最终,本场比赛的比分为托特纳姆热刺1-3利",
"target": " 北京时间1月29日凌晨4时,英超联赛第20轮迎来一场强强对话,热刺坐镇主场迎战利物浦。 热刺vs利物浦,比赛看点如下: 第一:热刺能否成功复仇?双方首回合,热刺客场1-2被利物浦绝杀,赛后穆里尼奥称最好的球队输了,本轮热刺主场迎战利物浦,借着红军5轮不胜的低迷状态,能否成功复仇? 第二:利物浦近",
"labelB": "0"
}一般来说,完成这个任务至少需要两个模型,毕竟A、B两种类型的分类标准是不一样的,如果要做得更精细的话,应该还要做成6个模型。但问题是,如果独立地训练6个模型,那么往往比较费力,而且不同任务之间不能相互借鉴来提升效果,所以很自然地我们应该能想到共享一部分参数变成一个多任务学习问题。
模型简介 #
当然,如果看成是常规的多任务学习问题,那又太一般化了。针对这几个任务“形式一样、标准不一样”的特点,笔者构思了通过条件LayerNorm(Conditional Layer Normalization)来实现用一个模型做这6个子任务。
关于条件LayerNorm,我们之前在文章《基于Conditional Layer Normalization的条件文本生成》也介绍过,虽然当时的例子是文本生成,但是它可用的场景并不局限于此。简单来说,条件LayerNorm就是一种往Transformer里边加入条件向量来控制输出结果的一种方案,它把条件加入到LayerNorm层的$\beta,\gamma$中。
对于这个比赛的6个任务而言,我们只需要将任务类型作为条件传入到模型中,就可以用同一个模型处理不同6个不同的任务了,示意图如下:
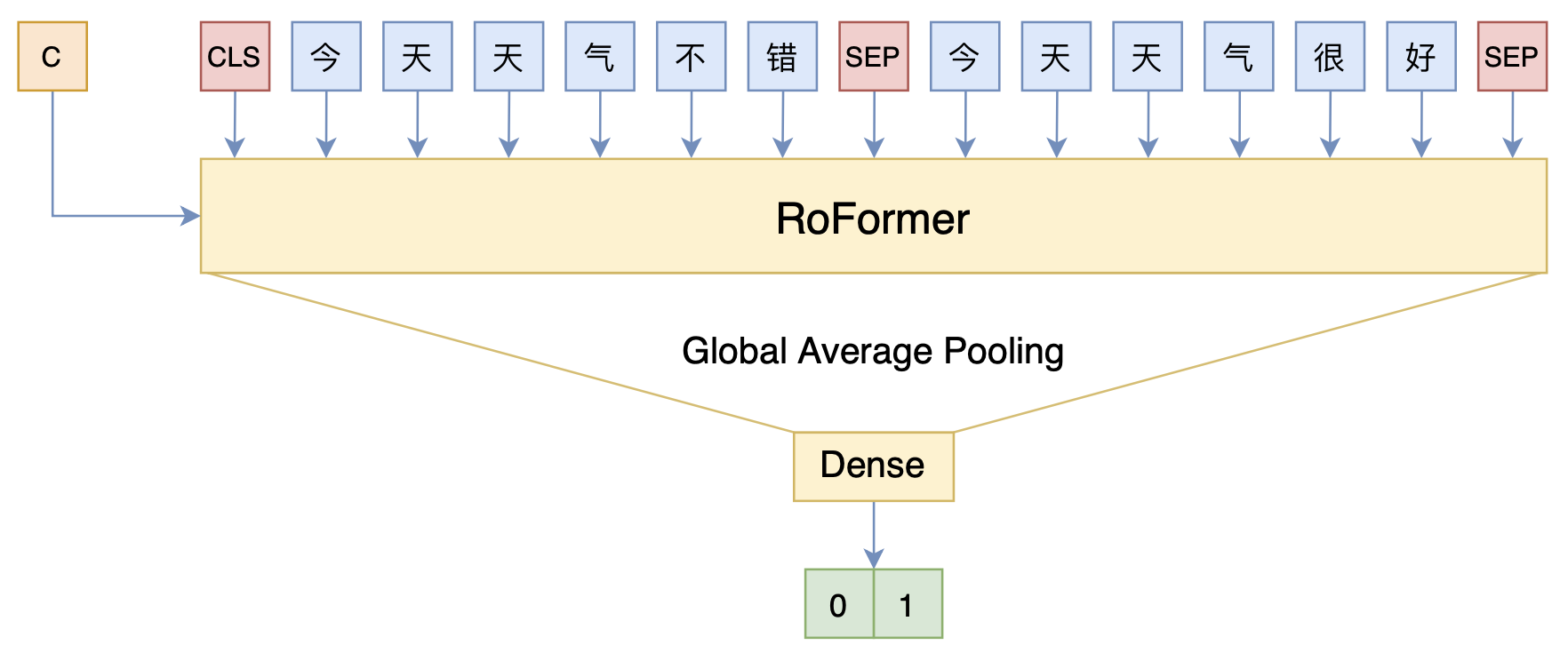
用条件LayerNorm处理多个相似任务
这样一来,整个模型都是共用的,只是在输入句子的时候同时将任务类型的id作为输入,实现了参数的最大共用化。
代码参考 #
关于条件LayerNorm的实现,早已内嵌在bert4keras中,所以想到这个设计后,用bert4keras来实现就是水到渠成了,参考代码如下:
代码使用了RoFormer为基准模型,这主要考虑到在“长长匹配”中,两个文本拼接起来的总长度还是很长的,用以词为单位的RoFormer可以缩短序列长度,同样的算力下可以处理更长的文本,而且RoFormer所使用的RoPE位置编码理论上可以处理任意长的文本。代码测了几次,线下的F1为0.74左右,线上测试集提交后的F1为0.73上下。在3090上测试,单个epoch好像是1个小时左右,跑4、5个epoch就差不多了。
现在的代码是所有数据混合在一起然后随机训练的,这样做有个小缺点,就是原来的序列长度比较短的样本也填充到最大长度进行训练了,导致了短序列样本训练速度变慢(当然肯定比你独立训练6个模型要快),可以做的优化是在分batch的时候尽量让同一个batch的样本长度相近,不过我懒得写了,留给大家优化吧~
文章小结 #
本文分享了一个搜狐文本匹配的baseline,主要是通过条件LayerNorm来增加模型的多样性,以实现同一模型处理不同类型的数据、形成不同输出的目的。
转载到请包括本文地址:https://www.spaces.ac.cn/archives/8337
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Apr. 16, 2021). 《搜狐文本匹配:基于条件LayerNorm的多任务baseline 》[Blog post]. Retrieved from https://www.spaces.ac.cn/archives/8337
@online{kexuefm-8337,
title={搜狐文本匹配:基于条件LayerNorm的多任务baseline},
author={苏剑林},
year={2021},
month={Apr},
url={\url{https://www.spaces.ac.cn/archives/8337}},
}

June 8th, 2021
请教下苏神,请问您有没有考虑过在输入前就将conditonal embedding 与token embedding, pos embedding相加作为input embedding送进去? 想请教下您对于这种方法的看法和分析~ 谢谢苏神!
没啥特别,可能会效果会略差,也可能效果一样但是收敛略慢。
May 31st, 2022
苏神您好,我最近在做的一个任务与本篇文章内容相似,具体是将两个多标签分类任务进行多任务学习,但是这两个任务的标签数不一致,一个任务是有20个标签,另一个任务时25个标签,这种情况下,在最后一层Dense是不是需要按照多的那一个任务的标签数进行分类,以您的经验,这样是否会对标签少的任务性的影响比较大。对于标签数量不一致和多标签分类任务进行多任务学习,您有什么建议。
你这两个任务互相包含的吗?如果不是,应该是做一个45标签的多标签分类才对吧?
两个任务是有相互包含的,两个任务中有部分标签定义是一致的(A任务中的标签a等于B任务中的标签a),有部分标签是交叉的关系(比如说,A任务中的标签b,在B任务中会被拆成标签b1和标签b2),还有一部分标签是完全不一样的(A任务中有标签c,B任务中有标签d),而且之后还会有更多的相类似的任务,每个任务都是相似的,任务的区别是场景不一样,标签的定义会有一些差别。这种情况下您有什么好的建议吗?
我使用本文的方式进行了一次尝试,在最后的Dense使用的是25类的标签,最终的效果和每个任务使用独立模型的性能差不多,两个任务的数据是相互独立的来源。如果要进一步尝试,是不是可以考虑把两个任务相同标签定义的数据进行任务共享(就是将A任务的a标签对应的数据也作为B任务a标签对应的数据),然后在进行训练。就我现在了解到的多任务学习一般情况下是会比单任务的结果好一些,但就我现在尝试的结果来看,是差不多的,这个结果您是怎么理解的?
同样用条件LayerNorm,最后用不同的Dense也行呀,不同类型的分类,没必要共用Dense。
February 28th, 2023
苏神您好,想请问一下如果按照本文的逻辑来看,那么只要是各个任务模型结构一致,任务目标高度雷同的多任务学习是不是都可以采用这种基于条件LayerNorm的方式进行处理,也就是下游任务可以自由切换。比如我想做一个多任务的实体识别,模型基于bert+globalpointer也可以用这个方式处理呢?
前面部分的理解没错,但是实体识别的问题在于不同任务要识别的实体类型通常是不一样的,所以更多的是修改输出层(也就是GlobalPointer)。如果你的场景是要识别的实体类型是一样的,那么可以套用这个思路。